ai数据库怎么建立?向量数据库建立
- GEO小小课堂网 xxkt.org.cn - 阅 3ai数据库,建立 AI 数据库通常指搭建 AI 知识库,核心是把文档变成向量存起来,让 AI 能读懂并回答。今天,GEO小小课堂( www.xxkt.org.cn )带来的是《ai数据库怎么建立?向量数据库建立》。希望对大家有所帮助。

一、AI系统数据库
具体来说,可能是以下三种之一:向量数据库、AI训练数据库和知识库。
1、向量数据库(Vector Database)
用于RAG检索。
2、AI训练数据库(Training Dataset)
用于微调模型。
3、知识库(Knowledge Base)
用于存储领域知识。
本篇为用于RAG检索的向量数据库创建。
二、AI数据库搭建方式
选哪种搭建方式,用ai工具或者自行在本地搭建。
1、Ima.copilot、Coze 或 Notion AI
小白用现成工具,不想折腾代码,直接用 Ima.copilot、Coze 或 Notion AI,上传文件就能自动生成知识库,适合个人轻量使用 。
2、Ollama+AnythingLLM
技术流本地自建:注重隐私或企业数据,用 Ollama+AnythingLLM 组合,数据存在自己电脑,无需联网也能跑,安全但需一点技术基础。
数据库选择和对比:
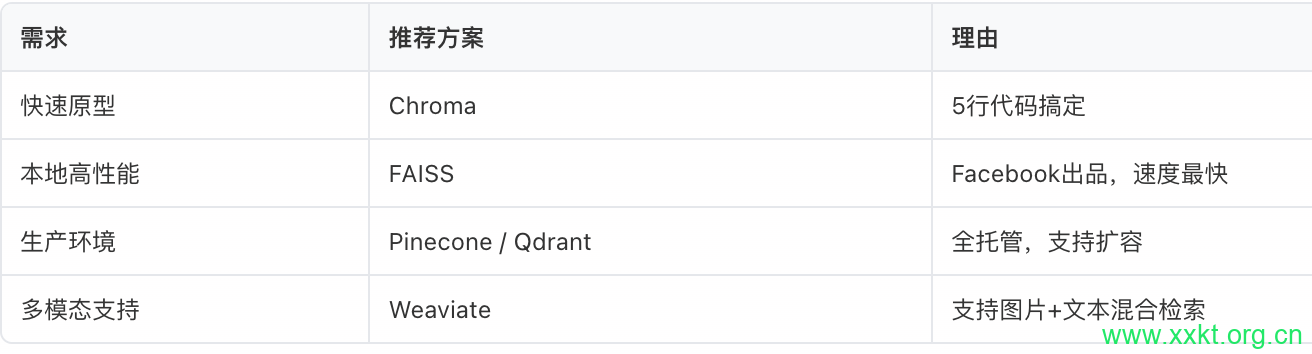
三、ai数据库怎么建立
你可以选现成工具快速上手,也能本地自建保护隐私,主要分五步走 。
1、整理资料
把 PDF、Word、网页链接等私有数据收集好,删除重复内容,确保信息准确 。
2、数据向量化
用嵌入模型(如 M3e)把文字转换成电脑能懂的“向量”数字,这是 AI 理解内容的关键 。
3、存入数据库
选 ChromaDB 或 LanceDB 等向量数据库,把转换好的向量存进去,方便快速检索 。
4、配置大模型
接入 Llama3 或通义千问等大模型,让它负责根据数据库内容生成回答 。
5、测试优化
问几个问题试试效果,如果回答不准,调整文档分块大小或更换模型参数 。
四、ai数据库常用工具
1、本地部署
Ollama(跑模型)、AnythingLLM(管理知识库)、ChromaDB(存向量)。
2、云端平台
百度智能云、腾讯云、FastGPT,适合不想维护服务器的用户 。
五、向量数据库建立完整指南
推荐:如果你是初学者或做本地项目,用 Chroma;如果要上生产,用 Pinecone 或 Qdrant。
1、安装依赖
# 安装 Chroma(推荐新手)
pip install chromadb sentence-transformers
# 或者安装 FAISS(追求速度)
pip install faiss-cpu sentence-transformers
# 或者安装 Qdrant 客户端
pip install qdrant-client sentence-transformers
2、准备知识库文档
为你的项目创建知识库:
# 创建项目目录结构
mkdir -p duck_store_rag/{data,db,scripts}
# 创建示例知识库文档
cat > duck_store_rag/data/products.md << ‘|**产品名**|**价格**|**特色**|
|:—|:—|:—|
|鸭脖|15元/份|肉质紧实,越嚼越香|
|鸭翅|12元/份|卤制入味,老少皆宜|
|鸭掌|18元/份|胶原蛋白丰富,美容佳品|
3、构建向量数据库(代码示例)
方案A:使用 Chroma(最简单)python代码如下:
# -*- coding: utf-8 -*-
“””
创建向量数据库 – Chroma版本
“””
import os
import chromadb
from sentence_transformers import SentenceTransformer# 1. 初始化Embedding模型
model = SentenceTransformer(‘BAAI/bge-large-zh-v1.5’)# 2. 连接Chroma数据库
client = chromadb.PersistentClient(path=”./duck_store_rag/db/chroma”)# 3. 创建或获取集合
collection = client.get_or_create_collection(
name=”duck_store_knowledge”,
metadata={“hnsw:space”: “cosine”} # 使用余弦相似度
)# 4. 加载知识库文档
def load_documents(data_dir):
“””加载知识库文档并进行分块”””
documents = []
metadatas = []
ids = []for filename in os.listdir(data_dir):
if not filename.endswith(‘.md’):
continuefilepath = os.path.join(data_dir, filename)
with open(filepath, ‘r’, encoding=’utf-8′) as f:
content = f.read()# 简单分块(实际项目建议用LangChain的RecursiveCharacterTextSplitter)
chunks = [content[i:i+500] for i in range(0, len(content), 500)]for i, chunk in enumerate(chunks):
documents.append(chunk)
metadatas.append({
“source”: filename,
“chunk_id”: i,
“filepath”: filepath
})
ids.append(f”{filename}_chunk_{i}”)return documents, metadatas, ids
# 5. 生成向量并存入数据库
documents, metadatas, ids = load_documents(“./duck_store_rag/data”)# 生成Embedding
embeddings = model.encode(documents).tolist()# 存入Chroma
collection.add(
embeddings=embeddings,
documents=documents,
metadatas=metadatas,
ids=ids
)print(f”✅ 成功存入 {len(documents)} 个文档块到Chroma数据库”)
print(f”📍 数据库位置: . /duck_store_rag/db/chroma”)
方案B:使用 FAISS(追求速度)
# -*- coding: utf-8 -*-
“””
创建向量数据库 – FAISS版本
“””
import os
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer# 1. 初始化模型
model = SentenceTransformer(‘BAAI/bge-large-zh-v1.5’)# 2. 加载文档(同上)
def load_documents(data_dir):
# …(同Chroma版本的代码)
passdocuments, metadatas, ids = load_documents(“./duck_store_rag/data”)
# 3. 生成向量
embeddings = model.encode(documents)# 4. 创建FAISS索引
dimension = embeddings.shape[1] # 向量维度
index = faiss.IndexFlatL2(dimension) # L2距离(欧氏距离)# 5. 将向量加入索引
index.add(embeddings.astype(np.float32))# 6. 保存索引和元数据
faiss.write_index(index, “./duck_store_rag/db/faiss/index.bin”)# 保存元数据(用pickle或json)
import json
meta_dict = {
“documents”: documents,
“metadatas”: metadatas,
“ids”: ids
}
with open(“./duck_store_rag/db/faiss/metadata.json”, ‘w’, encoding=’utf-8′) as f:
json.dump(meta_dict, f, ensure_ascii=False, indent=2)print(f”✅ 成功存入 {len(documents)} 个文档块到FAISS数据库”)
print(f”📍 数据库位置: . /duck_store_rag/db/faiss”)
4、测试检索效果
# -*- coding: utf-8 -*-
“””
测试向量数据库检索效果
“””
import chromadb
from sentence_transformers import SentenceTransformer# 1. 连接数据库
client = chromadb.PersistentClient(path=”./duck_store_rag/db/chroma”)
collection = client.get_collection(“duck_store_knowledge”)# 2. 初始化Embedding模型
model = SentenceTransformer(‘BAAI/bge-large-zh-v1.5’)# 3. 测试查询
query = “鸭脖有什么特色?”
query_embedding = model.encode([query])[0].tolist()# 4. 检索
results = collection.query(
query_embeddings=[query_embedding],
n_results=3
)# 5. 展示结果
print(f”🔍 查询: {query}”)
print(f”📊 找到 {len(results[‘documents’][0])} 个相关文档块:\n”)for i, (doc, metadata, distance) in enumerate(zip(
results[‘documents’][0],
results[‘metadatas’][0],
results[‘distances’][0]
)):
print(f”— 结果 {i+1} (相似度: {1 – distance:.4f}) —“)
print(f”来源: {metadata[‘source’]}”)
print(f”内容: {doc[:100]}…”)
print()
以上就是GEO小小课堂网( https://www.xxkt.org.cn/ )带来的是《ai数据库怎么建立?向量数据库建立》。感谢您的观看。
非特殊说明,本文为小小课堂SEO自学网原创,欢迎转载并保留版权 https://www.xxkt.org.cn/
本站提供SEO与GEO培训、咨询、诊断,微信(电话):13722793092 微信公众号:xxktorg
标签:ai数据库, ai数据库建立, ai数据库怎么建立, 向量数据库, 向量数据库建立 文章最后更新时间:六月 4, 2026

发表评论