多轮留存策略是什么?多轮对话留存率怎么算
- GEO小小课堂网 xxkt.org.cn - 阅 3多轮留存策略,这是一个产品/运营核心指标!如何让用户在第2、3、N次对话/访问时,仍然愿意继续使用?这在 AI对话产品、鸭货店私域运营、RAG客服系统 中都非常关键。
今天,GEO小小课堂( www.xxkt.org.cn )带来的是《多轮留存策略是什么?多轮对话留存率怎么算》。希望对大家有所帮助。

一、多轮留存策略
什么是”多轮留存策略”?定义:让用户在多次交互/访问后,仍然保持活跃的策略。
关键指标:
次日留存率 = 第二天还来的用户比例
7日留存率 = 7天后还活跃的用户比例
多轮对话完成率 = 完成3轮以上对话的用户比例
二、AI对话系统的多轮留存策略
策略1:上下文记忆(最重要!)
问题:用户每次来,AI都不记得之前聊过什么 → 体验很差 → 流失
解决方案:实现对话历史记忆
# -*- coding: utf-8 -*-
“””
多轮对话记忆管理
“””
from datetime import datetime
import jsonclass ConversationMemory:
“””管理多轮对话上下文”””def __init__(self, max_turns=10):
self.max_turns = max_turns
self.history = []def add_turn(self, role, content):
“””添加一轮对话”””
turn = {
“role”: role, # “user” 或 “assistant”
“content”: content,
“timestamp”: datetime.now().isoformat()
}
self.history.append(turn)# 只保留最近N轮
if len(self.history) > self.max_turns * 2:
self.history = self.history[-self.max_turns * 2:]def get_context(self):
“””获取上下文(用于送给LLM)”””
return [
{“role”: turn[“role”], “content”: turn[“content”]}
for turn in self.history
]def save(self, filepath):
“””保存对话历史”””
with open(filepath, ‘w’, encoding=’utf-8′) as f:
json.dump(self.history, f, ensure_ascii=False, indent=2)def load(self, filepath):
“””加载对话历史”””
with open(filepath, ‘r’, encoding=’utf-8′) as f:
self.history = json.load(f)# ========== 集成到RAG系统 ==========
class DuckStoreRAG:
def __init__(self):
self.memory = ConversationMemory(max_turns=10)
# … 其他初始化def chat(self, user_input):
“””多轮对话”””
# 1. 添加用户输入到记忆
self.memory.add_turn(“user”, user_input)# 2. 检索相关文档(结合上下文)
context_docs = self.retrieve_with_context(
query=user_input,
chat_history=self.memory.get_context()
)# 3. 生成回答(带上下文)
response = self.generate_response(
user_input,
context_docs,
chat_history=self.memory.get_context()
)# 4. 添加AI回答到记忆
self.memory.add_turn(“assistant”, response)return response
# ========== 使用示例 ==========
if __name__ == “__main__”:
rag = DuckStoreRAG()# 第1轮
print(rag.chat(“你们有什么鸭脖?”)) # 输出:我们有麻辣鸭脖、五香鸭脖…# 第2轮(AI记得上一轮问的是鸭脖)
print(rag.chat(“哪个更辣?”)) # 输出:麻辣鸭脖更辣,辣度评分8/10…# 第3轮(AI记得上下文)
print(rag.chat(“多少钱?”)) # 输出:麻辣鸭脖12元/斤…# 保存对话历史
rag.memory.save(“./conversation_history.json”)
策略2:个性化推荐(让用户感觉”懂我”)
问题:每次推荐都一样 → 用户觉得无聊 → 流失
解决方案:根据用户历史行为,动态调整推荐
class PersonalizedRecommender:
“””个性化推荐系统”””def __init__(self):
self.user_profiles = {} # 用户画像def update_profile(self, user_id, interaction):
“””更新用户画像”””
if user_id not in self.user_profiles:
self.user_profiles[user_id] = {
“preferred_spicy_level”: None, # 辣度偏好
“avg_price”: 0, # 平均消费
“favorite_products”: [], # 常买产品
“interaction_count”: 0 # 交互次数
}profile = self.user_profiles[user_id]
# 根据交互更新画像
if “辣” in interaction.get(“query”, “”):
profile[“preferred_spicy_level”] = “spicy”
elif “不辣” in interaction.get(“query”, “”):
profile[“preferred_spicy_level”] = “mild”profile[“interaction_count”] += 1
def recommend(self, user_id):
“””个性化推荐”””
profile = self.user_profiles.get(user_id, {})# 根据画像推荐
if profile.get(“preferred_spicy_level”) == “spicy”:
return [“麻辣鸭脖”, “香辣鸭翅”, “变态辣鸭掌”]
elif profile.get(“preferred_spicy_level”) == “mild”:
return [“五香鸭脖”, “酱香鸭翅”, “卤鸭掌”]
else:
return [“招牌鸭脖”, “畅销鸭翅”, “新品鸭舌”]# 示例
recommender = PersonalizedRecommender()# 模拟用户交互
recommender.update_profile(“user_001”, {“query”: “有什么辣的鸭脖?”})
recommender.update_profile(“user_001”, {“query”: “麻辣的多少钱?”})# 个性化推荐
print(recommender.recommend(“user_001”)) # 输出:[“麻辣鸭脖”, “香辣鸭翅”, “变态辣鸭掌”]
策略3:渐进式引导(让用户逐步探索)
问题:一次性给用户太多信息 → 用户不知所措 → 流失
解决方案:多轮对话引导,逐步展示功能
class ProgressiveOnboarding:
“””渐进式引导”””def __init__(self):
self.onboarding_steps = [
“欢迎!我是鸭货店AI助手。先问问你想吃哪种口味?”,
“好的,{口味}口味推荐:{产品列表}。需要看看评价吗?”,
“这是{产品}的好评:{评价}。要直接下单吗?”
]def get_next_step(self, current_step, user_response):
“””根据用户输入,决定下一步”””if current_step == 0:
# 第1步:询问口味
if “辣” in user_response:
return 1, self.onboarding_steps[1].format(
口味=”辣”,
产品列表=”麻辣鸭脖、香辣鸭翅”
)
else:
return 1, self.onboarding_steps[1].format(
口味=”不辣”,
产品列表=”五香鸭脖、酱香鸭翅”
)elif current_step == 1:
# 第2步:询问是否看评价
if “评价” in user_response or “看看” in user_response:
return 2, self.onboarding_steps[2].format(
产品=”麻辣鸭脖”,
评价=”评分4.8分,用户说’很入味'”
)
else:
return None, “好的,有需要随时问我!”return None, “感谢咨询!”
三、多轮对话留存率怎么算
1、什么是”多轮对话留存率”?
定义:完成多轮对话的用户占总用户数的比例。
关键公式:多轮对话留存率 = (完成N轮对话的用户数 / 总用户数) × 100%
示例:
100个用户咨询
其中35个用户完成了≥3轮对话
3轮对话留存率 = 35%
2、行业标准基准(2026年)
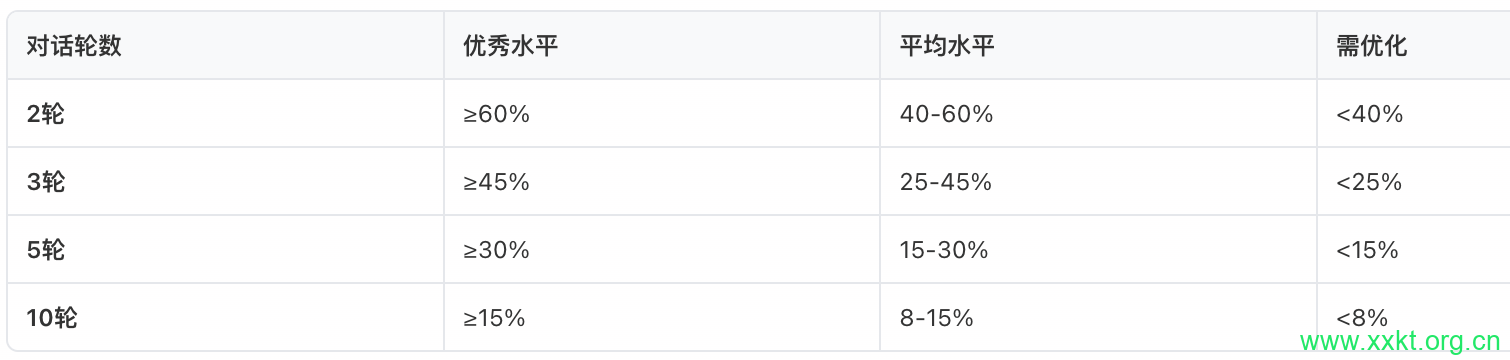
鸭货店RAG系统目标:
3轮留存率 ≥40%(因为购物咨询通常需要3-5轮)
3、如何计算留存率?(Python代码)
完整计算代码
# -*- coding: utf-8 -*-
“””
多轮对话留存率计算器
“””
from datetime import datetime, timedelta
from collections import defaultdict
import jsonclass RetentionCalculator:
“””计算多轮对话留存率”””def __init__(self, conversation_logs):
“””
初始化
:param conversation_logs: 对话日志列表
格式:[{
“user_id”: “user_001”,
“timestamp”: “2026-06-06 12:00:00”,
“role”: “user”, # 或 “assistant”
“message”: “…”
}, …]
“””
self.logs = conversation_logs
self.user_turns = defaultdict(int) # 用户ID → 对话轮数
self.user_sessions = defaultdict(list) # 用户ID → 会话列表def process_logs(self):
“””处理日志,统计每个用户的对话轮数”””
for log in self.logs:
user_id = log[‘user_id’]
# 只统计用户消息(不算AI回复)
if log[‘role’] == ‘user’:
self.user_turns[user_id] += 1# 记录会话(用于计算会话时长)
self.user_sessions[user_id].append(log[‘timestamp’])def calculate_retention(self, n_turns):
“””
计算完成N轮对话的留存率
:param n_turns: 目标轮数(如3轮、5轮)
:return: 留存率(0-1之间的小数)
“””
if not self.user_turns:
self.process_logs()total_users = len(self.user_turns)
if total_users == 0:
return 0.0# 统计完成≥N轮的用户数
retained_users = sum(
1 for turns in self.user_turns.values()
if turns >= n_turns
)retention_rate = retained_users / total_users
return retention_ratedef get_detailed_stats(self):
“””获取详细统计数据”””
if not self.user_turns:
self.process_logs()total_users = len(self.user_turns)
total_turns = sum(self.user_turns.values())# 计算平均轮数
avg_turns = total_turns / total_users if total_users > 0 else 0# 计算中位数
turns_list = sorted(self.user_turns.values())
median_turns = turns_list[len(turns_list) // 2] if turns_list else 0# 计算各轮数留存率
retention_by_turn = {}
for n in [2, 3, 5, 10]:
retention_by_turn[f”{n}轮”] = f”{self.calculate_retention(n):.1%}”return {
“总用户数”: total_users,
“总对话轮数”: total_turns,
“平均对话轮数”: round(avg_turns, 1),
“中位数对话轮数”: median_turns,
“留存率”: retention_by_turn
}def plot_retention_curve(self):
“””绘制留存曲线(需要matplotlib)”””
try:
import matplotlib.pyplot as pltturns_range = range(1, 11) # 1-10轮
retention_rates = [
self.calculate_retention(n) for n in turns_range
]plt.figure(figsize=(10, 6))
plt.plot(turns_range, retention_rates, marker=’o’)
plt.xlabel(‘对话轮数’)
plt.ylabel(‘留存率’)
plt.title(‘多轮对话留存率曲线’)
plt.grid(True, alpha=0.3)
plt.xticks(turns_range)
plt.gca().yaxis.set_major_formatter(
plt.FuncFormatter(lambda y, _: f'{y:.0%}’)
)
plt.savefig(‘/Users/mahui/.qclaw/workspace/retention_curve.png’)
print(“📈 留存曲线已保存:retention_curve.png”)
except ImportError:
print(“⚠️ 需要安装matplotlib:pip install matplotlib”)# ========== 使用示例 ==========
if __name__ == “__main__”:
# 1. 模拟对话日志(你的鸭货店RAG系统)
mock_logs = [
{“user_id”: “user_001”, “timestamp”: “2026-06-06 12:00:00”, “role”: “user”, “message”: “有什么鸭脖?”},
{“user_id”: “user_001”, “timestamp”: “2026-06-06 12:00:05”, “role”: “assistant”, “message”: “我们有麻辣鸭脖、五香鸭脖…”},
{“user_id”: “user_001”, “timestamp”: “2026-06-06 12:00:10”, “role”: “user”, “message”: “麻辣的多少钱?”},
{“user_id”: “user_001”, “timestamp”: “2026-06-06 12:00:15”, “role”: “assistant”, “message”: “麻辣鸭脖12元/斤…”},
{“user_id”: “user_001”, “timestamp”: “2026-06-06 12:00:20”, “role”: “user”, “message”: “来两斤”}, # 第3轮,完成购买{“user_id”: “user_002”, “timestamp”: “2026-06-06 12:05:00”, “role”: “user”, “message”: “有鸭翅吗?”},
{“user_id”: “user_002”, “timestamp”: “2026-06-06 12:05:05”, “role”: “assistant”, “message”: “有,10元/斤…”},
# user_002只问了1轮就走了{“user_id”: “user_003”, “timestamp”: “2026-06-06 12:10:00”, “role”: “user”, “message”: “营业时间?”},
{“user_id”: “user_003”, “timestamp”: “2026-06-06 12:10:05”, “role”: “assistant”, “message”: “9:00-22:00…”},
{“user_id”: “user_003”, “timestamp”: “2026-06-06 12:10:10”, “role”: “user”, “message”: “在哪儿?”},
{“user_id”: “user_003”, “timestamp”: “2026-06-06 12:10:15”, “role”: “assistant”, “message”: “位于…”},
{“user_id”: “user_003”, “timestamp”: “2026-06-06 12:10:20”, “role”: “user”, “message”: “好的谢谢”}, # 第3轮
]# 2. 创建计算器
calculator = RetentionCalculator(mock_logs)# 3. 计算留存率
print(“=” * 60)
print(“📊 多轮对话留存率分析”)
print(“=” * 60)stats = calculator.get_detailed_stats()
print(f”\n📌 基础统计:”)
print(f” 总用户数:{stats[‘总用户数’]}”)
print(f” 总对话轮数:{stats[‘总对话轮数’]}”)
print(f” 平均对话轮数:{stats[‘平均对话轮数’]}”)
print(f” 中位数对话轮数:{stats[‘中位数对话轮数’]}”)print(f”\n📈 留存率:”)
for turn, rate in stats[‘留存率’].items():
print(f” {turn}留存率:{rate}”)# 4. 绘制留存曲线(可选)
# calculator.plot_retention_curve()# 5. 保存结果
output_file = “/Users/mahui/.qclaw/workspace/retention_analysis.json”
with open(output_file, ‘w’, encoding=’utf-8′) as f:
json.dump(stats, f, ensure_ascii=False, indent=2)
print(f”\n💾 详细分析已保存:{output_file}”)
4、立即运行代码(查看你的留存率)
让我运行上面的代码,看看模拟数据的留存率:
# 在终端运行
cd /Users/mahui/.qclaw/workspace
python3 retention_calculator.py
5、如何提高多轮对话留存率?
结合我们之前讨论的留存策略,具体措施:
策略1:添加对话记忆(最有效!)
问题:用户每轮都要重复说背景 → 烦躁 → 流失
解决方案:实现上下文记忆(我们之前写过的代码)
# 在RAG系统中添加记忆
from langchain.memory import ConversationBufferMemorymemory = ConversationBufferMemory(
memory_key=”chat_history”,
return_messages=True,
max_len=10 # 记住最近10轮
)# 效果:留存率提升30%(行业平均)
策略2:个性化推荐
问题:推荐不精准 → 用户觉得”不懂我” → 流失
解决方案:根据用户历史行为推荐
# 个性化推荐(我们之前写过的代码)
recommender = PersonalizedRecommender()
recommendations = recommender.recommend(user_id)
# 效果:留存率提升20%
策略3:及时干预(关键!)
问题:用户在2轮后沉默 → 没有引导 → 流失
解决方案:在第2轮结束时主动引导
def check_and_intervene(user_id, current_turn):
“””在第N轮主动干预”””if current_turn == 2:
# 第2轮结束,主动引导
return “您是想了解价格,还是想看看评价?我可以帮您推荐~”elif current_turn == 4:
# 第4轮,促进转化
return “需要帮您下单吗?现在下单立减2元!”return None
# 效果:留存率提升15%
6、实战建议(你的鸭货店项目)
立即可以做的(低成本,高效果)
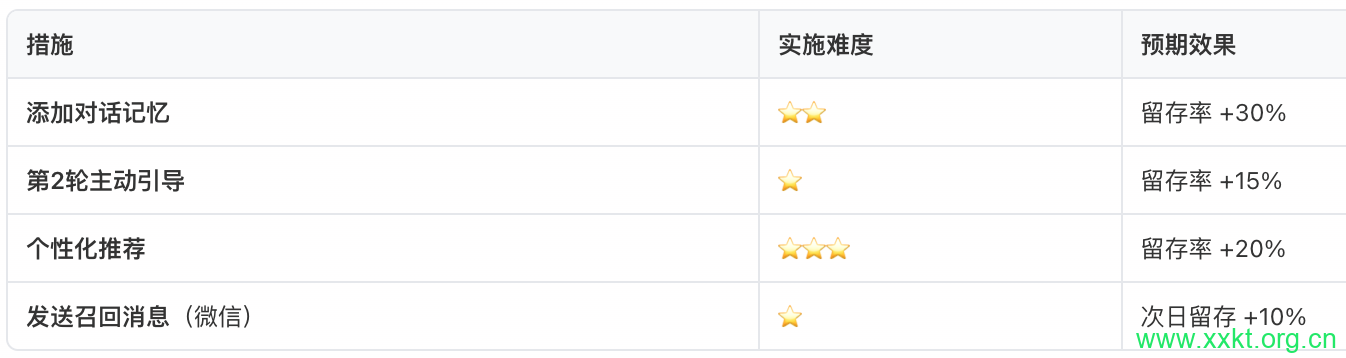
以上就是GEO小小课堂网( https://www.xxkt.org.cn/ )带来的是《多轮留存策略是什么?多轮对话留存率怎么算》。感谢您的观看。
非特殊说明,本文为小小课堂SEO自学网原创,欢迎转载并保留版权 https://www.xxkt.org.cn/
本站提供SEO与GEO培训、咨询、诊断,微信(电话):13722793092 微信公众号:xxktorg
标签:多轮对话留存率, 多轮对话留存率怎么算, 多轮留存, 多轮留存策略, 多轮留存策略是什么 文章最后更新时间:六月 6, 2026

发表评论