普林斯顿大学2024年GEO论文中文翻译版
- GEO小小课堂网 xxkt.org.cn - 阅 135普林斯顿大学2024年KDD会议的论文原文见右侧文章链接《GEO: Generative Engine Optimization》。今天,GEO小小课堂( www.xxkt.org.cn )带来的是《普林斯顿大学2024年GEO论文中文翻译版》。。希望对大家有所帮助。

摘要
大型语言模型(LLMs)的出现引领了一种新的搜索引擎样式,即使用生成模型来收集和总结信息以回答用户查询。这些生成引擎正在重塑搜索引擎,有望为用户查询提供个性化和精确的响应。然而,内容创作者却苦于无法控制自己的内容在这些引擎中的呈现方式。于是,生成引擎优化(GEO)应运而生,它为内容创作者提供了一套优化策略,以提升其在线可见度。为了评估GEO,我们推出了GEO-BENCH,这是一个包含来自不同来源的多样化用户查询的集合,每个查询都标记了相关类别和相应的搜索结果。我们的实验表明,GEO可以将源可见度提高多达40%,为内容创作者提供了实用的见解。GEO预示着信息发现系统的新时代,有望对搜索引擎开发者和内容创作者产生深远影响。
大型语言模型(LLMs)的出现引领了一种新的搜索引擎范式,这种搜索引擎使用生成模型来收集和总结信息以回答用户查询。我们将这种新兴技术正式纳入生成引擎(GEs)的统一框架下,它可以生成准确且个性化的回复,迅速取代了谷歌和必应等传统搜索引擎。生成引擎通常通过综合来自多个来源的信息并使用大型语言模型进行总结来满足查询需求。
虽然这一转变显著提高了用户效用和生成式搜索引擎的流量,但它给第三个利益相关者——网站和内容创作者带来了巨大挑战。鉴于生成式引擎的黑箱特性和快速发展的特性,内容创作者对其内容何时以及如何展示几乎没有控制权。随着生成式引擎的持续发展,我们必须确保创作者经济不会处于不利地位。
为了解决这一问题,我们推出了生成引擎优化(GEO),这是首个创新范式,通过灵活的黑盒优化框架来优化和定义可见性指标,从而帮助内容创作者提高其内容在生成引擎响应中的可见性。我们推出了GEO-bench,这是一个涵盖多个领域、包含多样化用户查询的大规模基准测试,以及相关的网络资源来回答这些查询,从而促进了系统性的评估。
通过严谨评估,我们证明GEO(生成引擎优化)能够在生成引擎响应中将可见度提升高达40%。此外,我们还展示了这些策略在不同领域的效果各不相同,这凸显了针对特定领域进行优化的必要性。我们的工作为信息发现系统开辟了新领域,对生成引擎的开发者和内容创作者都具有深远意义。1
引用文献
引用1 代码和数据可在 https://generative-engines.com/GEO/ 获取
允许免费制作本作品全部或部分的数字或纸质副本,以供个人或课堂使用,但前提是不得出于营利或商业利益而制作或分发副本,且副本的首页需保留本声明和完整引用。必须尊重除作者外其他方对本作品组成部分的版权。
允许以署名方式摘录。若需以其他方式进行复制、重新发布、发布到服务器或重新分发到列表,需事先获得特别许可和/或支付费用。请通过 permissions@ acm. org 申请许可。
KDD ’24,2024年8月25日至29日,西班牙巴塞罗那 © 2024 版权归所有者/作者所有。出版权已授权给ACM。
ACM ISBN 979-8-4007-0490-1/24/08
https://doi. org/10.1145/3637528.3671900
CCS概念
• 计算方法论 → 自然语言处理;机器学习;• 信息系统 → 网络搜索与信息发现。
关键词
生成模型、搜索引擎、数据集和基准测试 ACM 参考格式:
普拉纳杰·阿加瓦尔、维什瓦克·穆拉哈里、坦梅·拉杰普罗希特、阿什温·卡利安、卡蒂克·纳拉辛汉和阿米特·德什潘德。 2024. GEO:生成引擎优化。收录于第30届ACM SIGKDD知识发现与数据挖掘会议(KDD ’24)论文集,2024年8月25日至29日,西班牙巴塞罗那。美国计算机协会(ACM),纽约州纽约市,美国,12页。
https://doi .org/10.1145/3637528. 3671900
1 引言
三十年前,传统搜索引擎的发明彻底改变了全球的信息获取和传播方式[4]。这些搜索引擎功能强大,催生了学术研究、电子商务等诸多应用,但它们仅限于为用户查询提供相关网站列表。然而,近年来大型语言模型[5, 21]的成功为BingChat、谷歌的SGE和perplexity.ai等结合了传统搜索引擎和生成模型的更优秀系统铺平了道路。我们将这些系统称为生成引擎(GE),因为它们通过使用多个来源来搜索信息并生成多模态响应。
从技术上讲,生成引擎(图2)从数据库(如互联网)中检索相关文档,并使用大型神经网络模型根据这些来源生成回应,确保信息的来源可追溯,并为用户提供验证信息的方式。生成引擎对开发者和用户的有用性显而易见——用户能更快、更准确地获取信息,开发人员精心打造精准且个性化的回复,从而提升用户满意度和收入。然而,生成式引擎却对第三个利益相关者——网站和内容创作者不利。
与传统搜索引擎不同,生成式引擎通过直接提供内容,消除了用户浏览网站的需求,这种精确且全面的回应可能会减少网站的有机流量,并影响其可见度[16]。数以百万计的小企业和个人依赖网络流量和可见度来维持生计,生成引擎将极大地扰乱创作者经济。此外,生成引擎的黑箱性质和专有性使得内容创作者难以控制和理解他们的内容是如何被接收和呈现的。
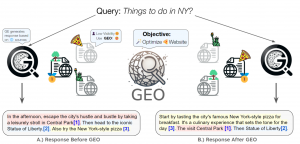
在本研究中,我们提出了首个以创作者为中心的通用框架,用于优化生成引擎的内容,我们将其命名为生成引擎优化(GEO),旨在助力内容创作者驾驭这一新的搜索范式。GEO具有灵活性,用于优化专有和闭源生成引擎网页内容可见性的黑盒优化框架(图1)。GEO会抓取源网站,并通过调整和校准展示方式、文本风格和内容,输出一个优化版本,以提高在生成引擎中的可见度。
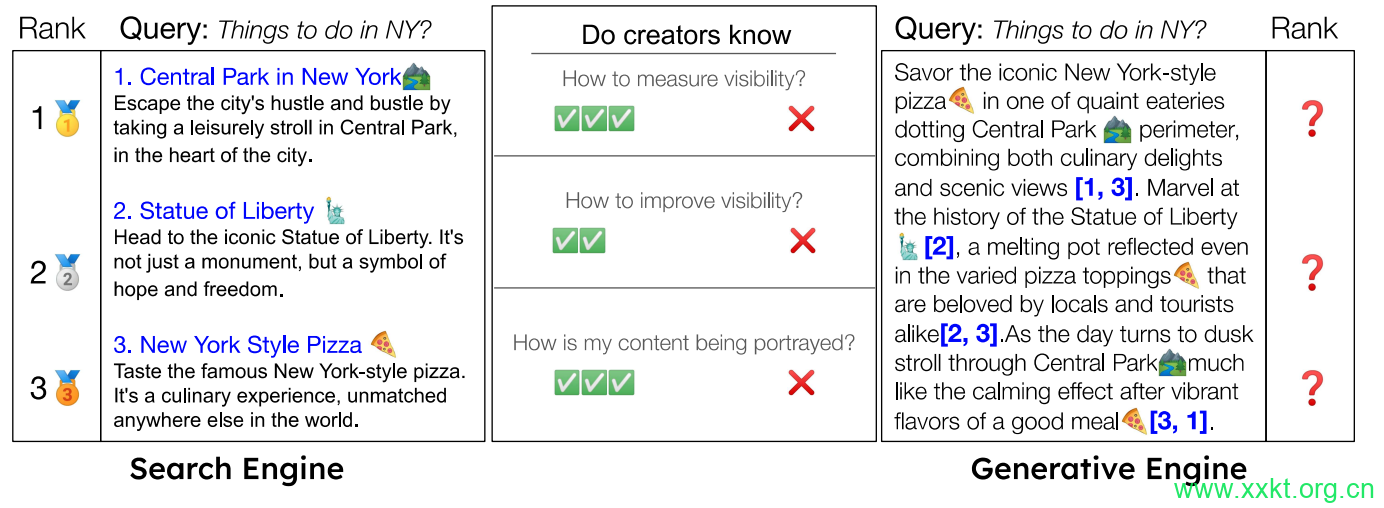
此外,GEO引入了一个灵活的框架,用于定义专为生成引擎量身定制的可见性指标,即生成式引擎的可见性比传统搜索引擎更加微妙且复杂(见图3)。在传统搜索引擎中,结果页的平均排名是衡量可见性的一个良好指标,因为它们会以线性列表的形式展示网站。然而,这并不适用于生成式引擎。生成式引擎提供丰富且结构化的响应,并将网站作为内联引用嵌入到响应中,这些引用的嵌入长度、位置和样式各不相同。
这迫切需要为生成引擎量身定制可见性指标,这些指标通过客观和主观两个视角,从多个维度(如引用与查询的相关性和影响力)来衡量归因源的可见性。
为了促进对生成式搜索引擎(GEO)方法的全面且准确的评估,我们提出了GEO-bench,这是一个由来自不同领域和来源的10000个查询组成的基准测试,专为生成式搜索引擎而设计。
通过系统评估,我们证明了我们提出的生成引擎优化方法能够在各种查询中将可见度提高多达40%,为内容创作者提供了有益的策略。除此之外,我们还发现,在内容中包含引用、相关来源的引述以及统计数据可以显著提高来源的可见度,在各种查询中的可见度提升超过40%。我们还展示了生成引擎优化在Perplexity.ai(一个真实的生成引擎)上的有效性,并证明了可见度提升高达37%。
综上所述,我们的贡献有三方面:
(1) 我们提出了生成引擎优化,这是首个面向网站所有者的通用优化框架,旨在帮助他们优化网站,生成引擎网站。生成引擎优化可以使网站的可见度在广泛范围内提高多达40%查询范围、领域以及现实世界中的黑盒生成引擎。
(2)我们的框架提出了一套专为生成引擎设计的全面可见性指标,使内容创作者能够通过定制的可见性指标灵活优化其内容。
(3)为了促进对生成引擎中GEO(生成对抗网络)方法的准确评估,我们提出了首个大规模基准测试,该测试由以下内容组成,来自广泛领域和数据集的多样化搜索查询,专为生成式引擎量身定制。
图1:我们提出的生成引擎优化(GEO)方法可优化网站,以提高其在生成引擎响应中的可见度。GEO的黑盒优化框架随后使原本缺乏可见度的披萨网站的网站所有者能够优化其网站,以提高在生成引擎下的可见度。此外,GEO的通用框架还允许内容创作者定义和优化其自定义可见性指标,使他们在这个新兴范式中拥有更大的控制权。
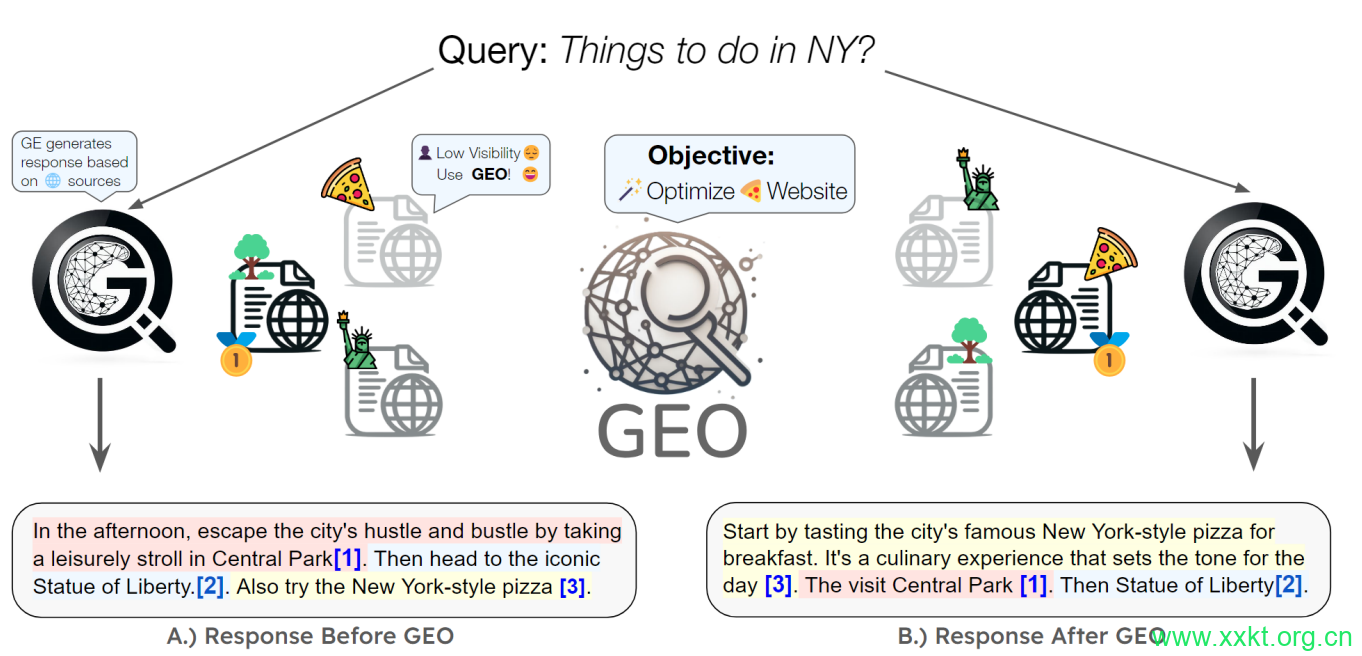
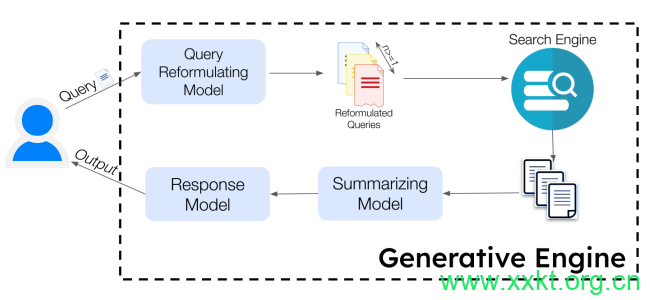
图2:生成引擎概览。生成引擎主要由一组生成模型和一个搜索引擎组成,用于检索相关文档。生成引擎接收用户查询作为输入,并通过一系列步骤生成最终响应,该响应基于检索到的资源,并附有内联归因信息。
2 公式与方法
2.1 生成引擎的构建
尽管已有众多生成引擎部署给数百万用户使用,但目前尚无标准框架。我们提出了一种设计,可容纳各种模块化组件。我们描述了一种生成引擎,该引擎包括多个后端生成模型和一个用于源检索的搜索引擎。
生成引擎(GE)接收用户查询𝑞𝑢,并返回自然语言响应𝑟,其中𝑃𝑈表示个性化用户信息。生成引擎可以表示为一个函数:
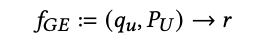
生成式引擎由两个关键组件构成:a.) 一组生成模型𝐺 = {𝐺1,𝐺2…𝐺𝑛},每个模型都服务于特定的目的,如查询重构或摘要生成;以及 b.) 一个搜索引擎𝑆𝐸,它根据给定的查询𝑞返回一组来源𝑆 = {𝑠1, 𝑠2…𝑠𝑚}。
我们在图2中展示了一个具有代表性的工作流程,在撰写本文时,该流程与BingChat的设计非常相似。这工作流将输入查询分解为一组更简单的查询,这些查询更易于搜索引擎处理。给定一个查询,查询重构生成模型𝐺1 = 𝐺𝑞𝑟会生成一组查询𝑄1 = {𝑞1, 𝑞2…𝑞𝑛},然后这些查询会被传递给搜索引擎𝑆𝐸以检索一组排序后的资源𝑆 = {𝑠1, 𝑠2, …, 𝑠𝑚}。
源集合𝑆被传递给一个总结模型𝐺2 = 𝐺𝑠𝑢𝑚,该模型为𝑆中的每个源生成一个总结𝑆𝑢𝑚𝑗,从而得到总结集合(𝑆𝑢𝑚 = {𝑆𝑢𝑚1, 𝑆𝑢𝑚2, …, 𝑆𝑢𝑚𝑚})。总结集合被传递给一个响应生成模型𝐺3 = 𝐺𝑟𝑒𝑠𝑝,该模型在源𝑆的支持下生成一个累积响应𝑟。
在本研究中,我们重点关注单轮生成引擎,但该公式可扩展至多轮对话生成引擎(见附录A)。响应𝑟通常是一个嵌入了引用的结构化文本。鉴于大型语言模型(LLMs)倾向于误导信息,这时引用就显得尤为重要。
具体来说,考虑一个由句子{𝑙1,𝑙2…𝑙𝑜}组成的回复𝑟。每个句子可能有一组引文作为支持,这些引文是检索到的文档集𝐶𝑖 ⊂ 𝑆的一部分。一个理想的生成引擎应确保回复中的所有陈述都有相关引文支持(高引文召回率),并且所有引文都能准确支持与其相关的陈述(高引文精确率)[14]。有关生成引擎的代表性回复,请参阅图3。
2.2 生成引擎优化
搜索引擎的出现催生了搜索引擎优化(SEO),这是一个帮助网站创建者优化其内容以提高搜索引擎排名的过程。更高的排名意味着更高的可见度和网站流量。然而,传统的SEO方法并不直接适用于生成引擎。这是因为与传统的搜索引擎不同,生成引擎中的生成模型不仅限于关键词匹配,并且在处理源文档和生成响应时使用语言模型,这使得对文本文档和用户查询的理解更加细致入微。
随着生成引擎迅速成为主要的信息传递范式,而SEO又无法直接适用,因此需要新的技术。为此,我们提出了生成引擎优化,这是一种新的样式,内容创建者的目标是在生成引擎的响应中提高其可见度(或曝光度)。我们定义了网站在引用响应𝑟中的可见度(也称为引用)𝑐𝑖,该可见度由函数𝐼𝑚𝑝(𝑐𝑖, 𝑟)表示,网站创建者希望将其最大化。
从生成引擎的角度来看,目标在于最大化与用户查询最相关的引用的可见性,即最大化。
![]()
在响应𝑟和𝑓的背景下,衡量引用𝑐𝑖与查询𝑞的相关性,这由生成引擎的精确算法设计决定,对终端用户而言是一个黑箱函数。此外,对于生成引擎而言,函数𝐼𝑚𝑝和𝑅𝑒𝑙都是主观的,且尚未明确定义,我们将在下文对其进行定义。
2.2.1 生成引擎的印象
在搜索引擎优化(SEO)中,一个网站的曝光度(或可见度)取决于其在一定查询范围内的平均排名。然而,生成式引擎的输出特性决定了需要不同的曝光度指标。与搜索引擎不同,生成式引擎会在一次响应中整合来自多个来源的信息。被引用网站的长度、独特性和呈现方式等因素决定了引用的真实可见度。
因此,如图3所示,虽然在传统搜索引擎中,响应页面上的简单排名是衡量印象和可见性的有效指标,但这些指标并不适用于生成式引擎的响应。
为了应对这一挑战,我们提出了一套印象指标,在设计时考虑了三个关键原则:
1)指标应与创作者相关;
2)指标应具有可解释性;
3)指标应易于广大内容创作者理解。
第一个指标是“字数”指标,即与引用相关的句子的标准化字数。从数学上讲,其定义为:
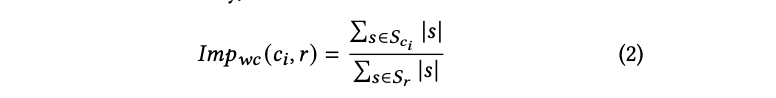
这里,𝑆𝑐𝑖是引用𝑐𝑖的句子集合,𝑆𝑛是回复中的句子集合,|𝑠|是句子𝑠中的单词数量。如果一个句子被多个来源引用,我们将单词数量平均分配给所有引用。直观上,单词数量越多,表明该来源在答案中发挥的作用越大,因此,用户对该来源的接触度就越高。
图3:在传统搜索引擎中,排名和可见性指标一目了然,它们会按排名列出网站来源,按字面内容排序。然而,生成引擎能生成丰富且结构化的回复,通常还会嵌入引用以单个区块的形式,彼此交错排列。
这使得排名和可见性变得微妙且多面。此外,与搜索引擎不同,尽管在提高可见性方面已进行了大量研究,但在生成式引擎响应中优化可见性仍然不明确。为了应对这些挑战,我们的黑盒优化框架提出了一系列精心设计的展示指标,创作者可以利用这些指标来衡量和优化其网站的表现,同时还可以自定义他们的展示指标。
然而,由于“字数统计”不受引文排名(例如,是否出现在首位)的影响,我们提出了一种基于位置的调整计数方法,该方法根据引文位置的指数衰减函数来降低权重:
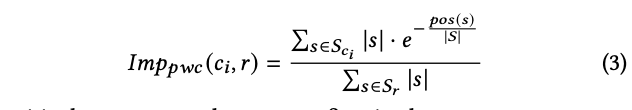
直观上,在回复中首先出现的句子更可能被阅读,且定义𝐼𝑚𝑝𝑝𝑤𝑐中的指数项给出,对这些引用给予更高的权重。因此,一个被引用的网站,尽管单词较少,但顶部可能具有更高的印象度,在回复中间或结尾引用的网站数量。
此外,选择指数衰减函数是有其动机的多项研究表明,点击率遵循幂律分布作为搜索引擎排名的一个函数[7, 8]。虽然上述,印象指标是客观且有充分依据的,但它们忽略了引用对用户注意力的影响的主观方面。为了解决这一问题,我们提出了“主观印象”,该指标综合考虑了被引用内容的相关性等多个方面对用户查询的材料、引用的影响、独特性,通过引用、主观立场、主观性呈现的材料,点击引用的次数、概率以及所呈现材料的多样性。我们使用G-Eval [15],这是目前最先进的评估方法,用于大型语言模型(LLMs)评估,以衡量这些子指标中的每一个。
2.2.2 网站生成引擎优化方法
为了提升印象指标,内容创作者必须做出改变,针对其网站内容,我们提出了几种生成式引擎无关策略,称为生成式引擎优化方法(GEO)。从数学角度来看,每种GEO方法都是一个函数𝑓:𝑊 → 𝑊 ′𝑖,其中,𝑊表示初始网页内容,𝑊′表示这是应用GEO方法后的修改内容。修改内容可能包括简单的风格调整,也可能包括,结构化格式的新内容。一个设计良好的GEO(全局优化)相当于一种黑盒优化方法,在不知道具体细节的情况下,生成引擎的精确算法设计,可以提升
提高网站的可见性,并对𝑊进行文本修改与具体查询无关。
在我们的实验中,我们使用大型语言模型对网站内容应用生成引擎优化方法,被提示对网站进行特定的风格和内容上的修改。特别是,基于定义一组特定所需特征的GEO方法,对源内容进行修改,因此,我们提出并评估了几种这样的方法:
1.权威性:修改源内容的文本风格,使其具有权威性,更具说服力和权威性;
2. 统计数据添加:修改内容应尽可能包含定量统计数据,而非定性讨论;
3. 关键词堆砌:修改内容在查询中包含更多关键词,这是经典搜索引擎优化(SEO)中常见的做法;
4. 引用来源:有引用的来源写出来;
5. 添加引用:分别添加来自可靠来源的相关引用和摘录;
6. 易于理解:简化语言网站;
7. 流畅度优化:则提升了网站文本的流畅度;
8. 独特词汇;独特字眼;
9.技术术语:涉及尽可能分别添加独特和技术性术语。
这些方法涵盖了网站所采用的多种通用策略,所有者可以快速实施并使用,无需考虑网站情况内容。此外,除了方法3、4和5,其余的这些方法增强了现有内容的呈现,以增加它对生成引擎的说服力或吸引力,而无需额外内容。另一方面,方法3、4和5可能需要某种形式的额外内容。为了分析我们方法的性能提升,对于每个输入的用户查询,我们随机
选择一个源网站进行优化,并应用每个(优化方案/方法)对同一来源分别采用GEO方法。我们建议读者参考有关GEO方法的更多详细信息,请参阅附录B.4。
3 实验设置
3.1 评估生成引擎
根据先前的研究[14],我们采用两步设置生成引擎设计。第一步涉及获取相关数据,输入查询的来源,然后是第二步,即使用大型语言模型(LLM),根据获取的资源生成响应。与之前的工作类似,我们不使用摘要,而是提供全部内容
对每个源的响应。由于上下文长度限制以及基于Transformer模型上下文大小的二次方扩展成本,仅从谷歌搜索引擎获取前五个搜索结果。对于每个查询的设置与所使用的工作流程非常相似,先前的研究成果以及商用燃气轮机(GE)所采用的一般设计,例如you.com和perplexity.ai。然后生成答案。使用与之前相同的提示,通过GPT3.5-Turbo模型[20]生成工作[14]。
我们在温度=0.7时采样了5个不同的响应,以减少统计偏差。在C.1节中,我们进一步评估了同一个生成引擎Perplexity.ai上的优化方法,这是一个商业化的部署生成引擎,凸显我们的泛化能力提出的生成引擎优化方法。
3.2 基准:GEO-bench
由于目前没有公开可用的数据集包含针对生成引擎相关的查询,我们精心打造了GEO-bench,这是一个由来自多个来源的10,000个查询组成的基准测试集,这些查询经过重新利用对于生成引擎,以及合成生成的查询。
该基准测试包含来自九个不同来源的查询,每个查询根据其目标领域、难度、查询内容进行进一步分类意图,以及其他维度。
数据集:
1. MS Macro;
2. ORCAS-1
3. Natural Questions:[1, 6, 13] 这些数据集包含真实的匿名用户查询来自Bing和Google搜索引擎。这三个搜索引擎合在一起代表搜索引擎相关研究中常用的数据集集合。然而,生成式引擎将被提出处理难度更大、更具体的查询,目的是从多个来源综合答案,而非单纯进行搜索它们。为此,我们重新利用了其他几个公开可用的资源数据集;
4. AllSouls:该数据集包含来自牛津大学万灵学院的论文问题,本数据集中的查询要求生成引擎进行适当的推理从多个来源收集信息。
5. LIMA:[25]包含了一些具有挑战性的问题,需要生成引擎来应对不仅汇总信息,还能进行适当的推理回答问题(例如,写一首短诗、编写Python代码)。
6. Davinci-Debate [14] 包含为辩论生成的辩论问题测试生成引擎。
7. Perplexity.ai Discover2(困惑度人工智能发现2)这些(注:原文“These”可能需要根据上下文具体翻译,此处为占位符)查询来源于Perplexity.ai的“发现”板块,该板块列出了平台上最新的热门查询。
8. ELI-53:这个数据集包含来自ELI5版块的问题,用户在该版块提问提出复杂的问题,并希望得到用简单、通俗易懂的语言给出的答案。
9. GPT-4生成的查询:为了补充查询的多样性,在分布方面,我们提示GPT-4 [21]生成一系列查询,来自不同领域(如科学、历史)且基于查询意图(例如,导航性、交易性)以及基于难度和生成响应的范围(例如,开放式、基于事实)。
我们的基准测试包含10,000个查询,分为8,000个、1,000个和训练集、验证集和测试集各占1K。我们保留真实世界的查询分布,我们的基准测试包含80%为信息查询,事务查询和导航查询各占10%。每个查询都通过清理文本进行增强谷歌搜索引擎前五个搜索结果的内容。
Tags:优化网站内容通常需要进行有针对性的更改基于任务的领域。此外,生成式模型的用户优化可能需要确定一种合适的方法,仅针对部分查询,需考虑多种因素,如领域、用户意图和查询性质。为了便于实现这一点,我们为每个(相关内容)打上标签,从七个不同类别中选择一个进行查询。在标注方面,我们采用GPT-4模型,并手动验证其高召回率和精确度在测试集上。
总体而言,GEO-bench包含来自25个不同领域的查询。例如艺术、健康和游戏;它涵盖了从简单到多方面的各种查询难度;包括9种不同类型的查询类型,如信息查询和事务查询并涵盖7种不同的分类。由于其特别设计的高GEObench是一个综合基准测试,其多样性、基准测试的规模以及其真实世界的特性,使其成为评估生成式模型的理想工具引擎,并作为评估引擎的标准测试平台。在本项及后续工作中,这些数据可用于多种目的。我们将提供更多详细信息关于附录B.2中的GEO-bench。
3.3 GEO方法
我们评估了9种不同的已提出的GEO方法,如文献所述第2.2.2节。我们将它们与一个基线进行比较,该基线用于衡量
未修改网站来源的印象指标。我们对其进行评估在完整的GEO-bench测试集上的方法。此外,为了减少为了减少结果差异,我们在五个不同的随机样本上进行了实验,数出种子并报告平均数。
3.4 评估指标
我们采用第2.2.1节中定义的印象指标。具体而言,我们采用了两个印象指标:1. 位置调整后的词数统计,结合了单词计数和位置计数。
为了分析各个组成部分的影响,我们还报告了分别计算两个子指标的分数。2. 主观印象,这是一个涵盖七个不同方面的主观指标方面:
1)引用句子与用户查询的相关性;
2)引用的影响,评估生成内容在多大程度上受到引用影响,回应取决于引文;
3)引文所呈现材料的独特性;
4)主观立场,衡量其重要性,从用户的角度来看的来源定位;
5)主观计数,即测量用户感知到的引用内容量;
6)用户点击的可能性以及引用次数;
7)所呈现材料的多样性。
这些子指标评估了内容创作者可以针对的多个方面有效提升一个或多个领域。每个子指标都会进行评估使用GPT-3.5,遵循类似于文中所述的方法论G-Eval [15]。在G-Eval中,向语言模型提供了一个基于表单的评估模板,以及一个由GE生成的响应带有引用。
该模型输出一个分数(通过采样计算得出)对每条引用进行多次评分。然而,由于G-Eval评分,如果它们校准得不好,我们会将它们归一化以具有相同的均值,并将方差作为位置调整词数,以实现公平和有意义的比较。我们提供了实际使用的确切模板附录B.3。
此外,所有印象指标都通过乘以一个常数因子进行归一化处理,以便印象的总和在回复中的所有引用次数等于1。在我们的分析中,我们进行了比较通过计算印象的相对提升程度来评估方法。
对于从源𝑆𝑖 ∈ {𝑠1, . . . , 𝑠𝑚}中生成的初始响应𝑟,以及一个修改后的响应𝑟′,印象的相对提升对于每个源𝑠𝑖测量方式为:
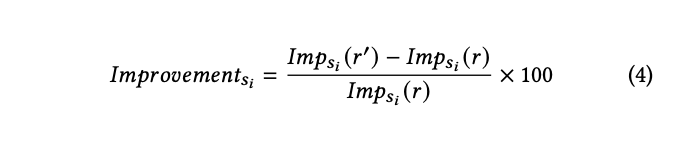
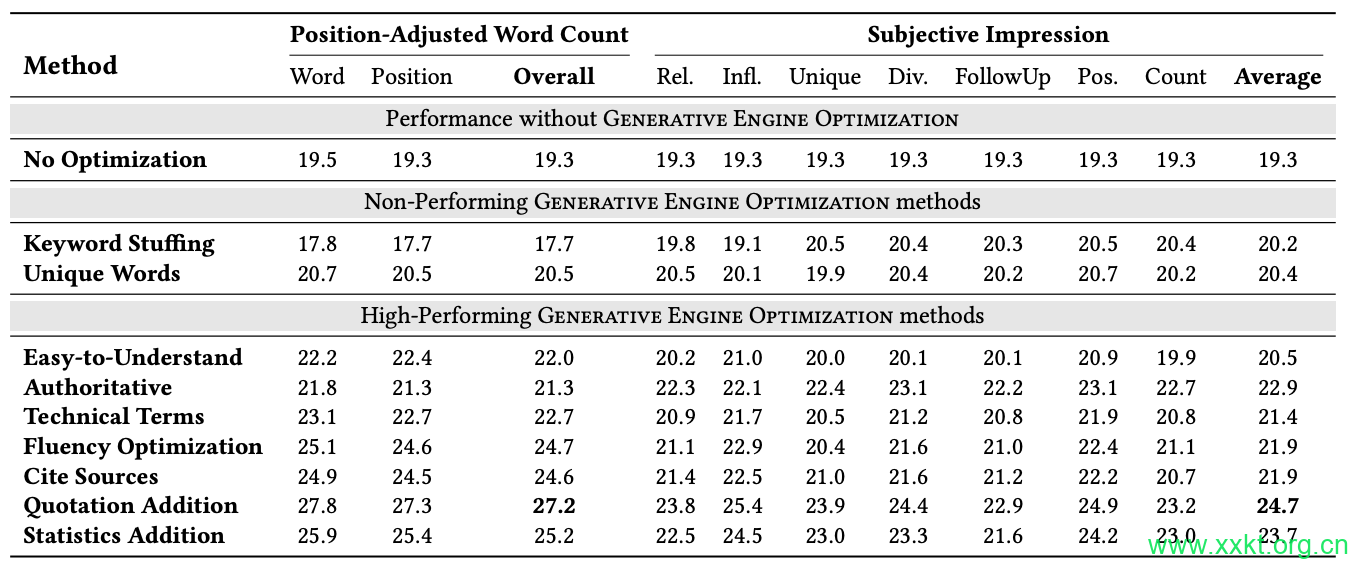
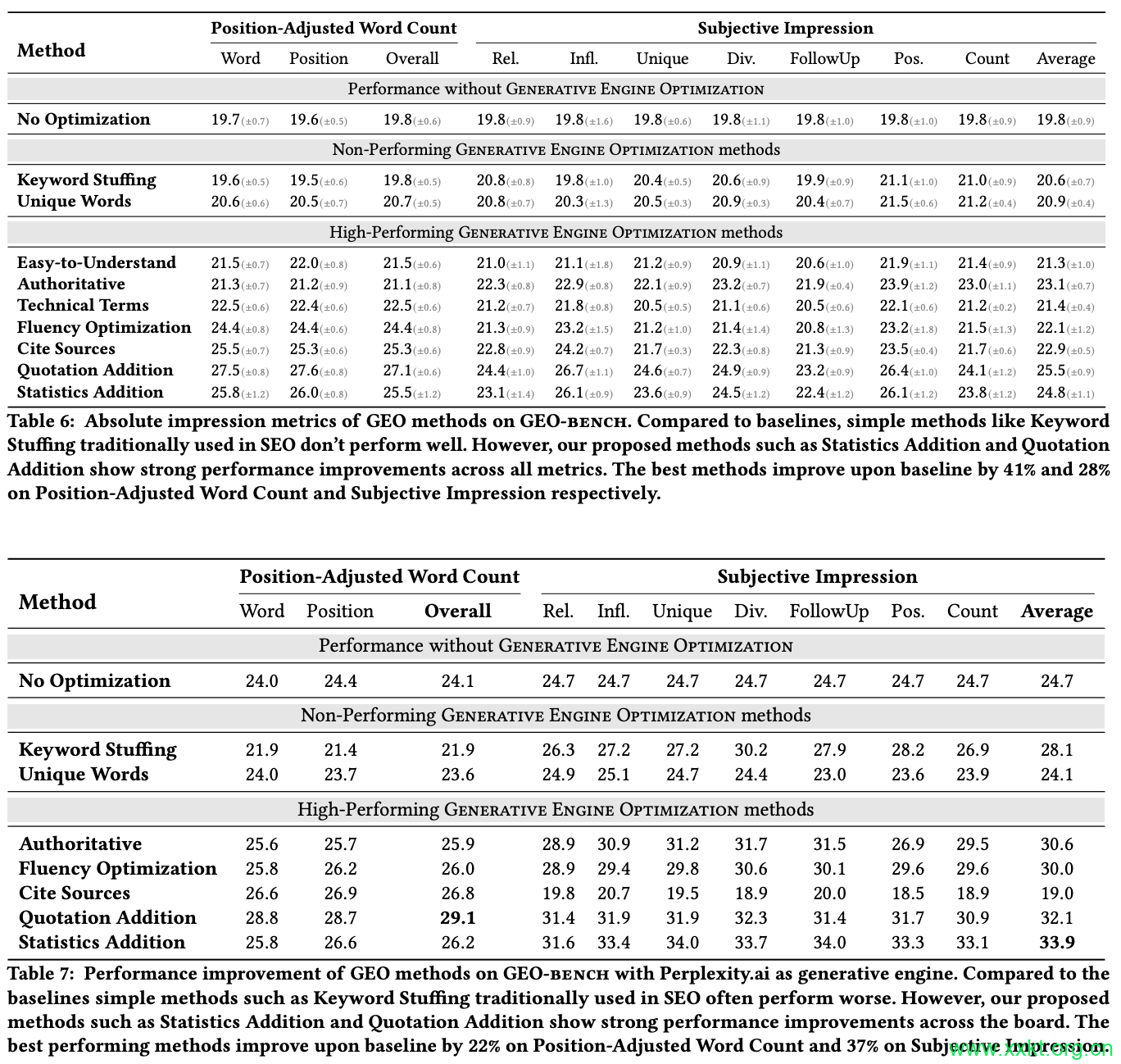
表1:GEO方法在GEO-bench上的绝对印象指标。性能通过两个指标及其子指标。与基线相比,传统上在搜索引擎优化(SEO)中使用的关键词堆砌等简单方法表现不佳。然而,我们提出的方法,如统计量添加和报价添加,显示出显著的性能提升在所有指标上,最佳方法在位置调整词数和主观性指标上分别比基线提高了41%和28%分别给出印象。为了提高可读性,主观印象评分会根据位置调整后的单词进行标准化计数得到相似的基线分数。
修改后的响应𝑟′是通过应用GEO方法产生的被评估为其中一个来源𝑠𝑖所选源𝑠𝑖优化参数是随机选择的,但在一段时间内保持不变所有GEO方法中的特定查询。
4 结果
我们评估了各种生成引擎优化方法旨在优化网站内容,使其在生成引擎的响应中具有更好的可见性,并与未经优化的基线进行比较。我们的评估使用了GEO-bench,这是一个多元化的基准测试来自多个领域和场景的用户查询。演出使用两个指标进行测量:位置调整词数和主观印象。前者考虑的是字数和引用在GE的响应中占据一定位置,而后者则计算多个主观因素,给出总体印象评分。
表1详细列出了不同方法在多个指标上的绝对印象指标。结果表明,我们的GEO方法在GEObench的所有指标上,这些方法的表现始终优于基线。这表明这些方法对不同情况的鲁棒性,查询,尽管查询具有多样性,但仍取得了显著改进。具体而言,我们表现最佳的方法,即引用来源、添加引文和添加统计数据,在位置调整词数指标上取得了30-40%的相对改进,并且主观印象指标提高了15-30%。这些方法包括增加相关统计数据(统计数据增加),以及融入可信的引用(添加引用),并包括引文网站内容中的可靠来源(引用来源)只需进行微小改动,即可显著提高在通用电气(GE)回复中的可见度,提升内容的可信度和丰富度。
有趣的是,文体上的变化,如提高流畅度,源文本的可读性(流畅度优化和易于理解)也显著提高了15-30%的可见度。
这表明生成引擎不仅重视内容,而且也是信息展示。
表2:通过GEO方法对搜索引擎中不同排名的来源的可见性变化。地理优化对排名较低的网站尤其有帮助。
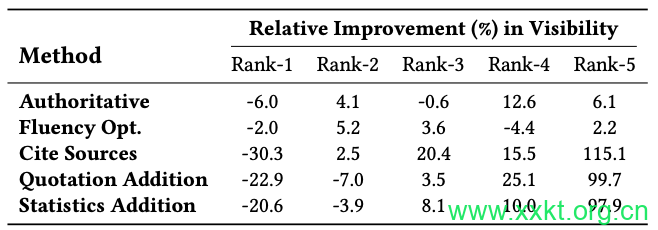
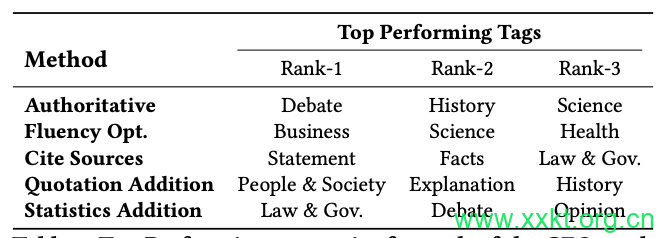
表3:每种GEO方法表现最佳的类别。网站所有者可以根据此表选择相关的地理区域策略在他们的目标领域。
此外,鉴于生成模型通常旨在遵循指令,人们会期望网站内容采用更具说服力和权威性的语气以提高可见度。然而,我们并未发现显著改善,这表明生成引擎对此类变化已具有一定的鲁棒性。这凸显了网站所有者需要专注于改进内容呈现方式和可信度。
最后,我们评估了关键词堆砌,即在网站内容中添加更多相关关键词。虽然这种方法在搜索引擎优化中被广泛应用,但我们发现它对生成式引擎的响应几乎没有改善或完全没有改善。这凸显出网站所有者需要重新思考针对生成式引擎的优化策略,因为在搜索引擎中有效的技术可能无法在这种新范式中取得成功。
5 分析
5.1 领域特定的生成引擎优化
在第4节中,我们展示了GEO在GEO-bench基准测试全集中的改进成果。然而,在在真实的搜索引擎优化(SEO)场景中,通常会进行特定领域的优化。考虑到这一点,并且鉴于我们在GEO-bench中为每个查询都提供了类别,我们将深入探讨不同GEO方法在这些类别中的表现。
表3详细列出了我们的GEO方法被证明最为有效的类别。对这些结果进行仔细分析后,我们得出了几个有趣的观察结果。例如,权威性显著提高了辩论式问题和与“历史”领域相关的查询的性能。这与我们的直觉相符,因为更具说服力的写作形式在辩论中可能更有价值。
同样,通过“引用来源”添加引用对于事实性问题尤其有益,这可能是因为引用为所陈述的事实提供验证来源,从而增强回复的可信度。不同地理信息(GEO)方法在不同领域的效果各不相同。例如,如表3第5行所示,在“法律与政府”等领域以及“观点”等问题类型中,通过添加相关统计数据(如“添加统计数据”所示)可显著提升其效果。
这表明,在特定情境下,数据驱动的证据可以提高网站的可见度。引用方法在“人与社会”、“解释”和“历史”领域,添加直接引述最为有效。这可能是因为这些领域通常涉及个人叙事或历史事件,而直接引述能为内容增添真实性和深度。
总体而言,我们的分析表明,网站所有者应努力针对特定领域对其网站进行有针对性的调整,以提高可见度。
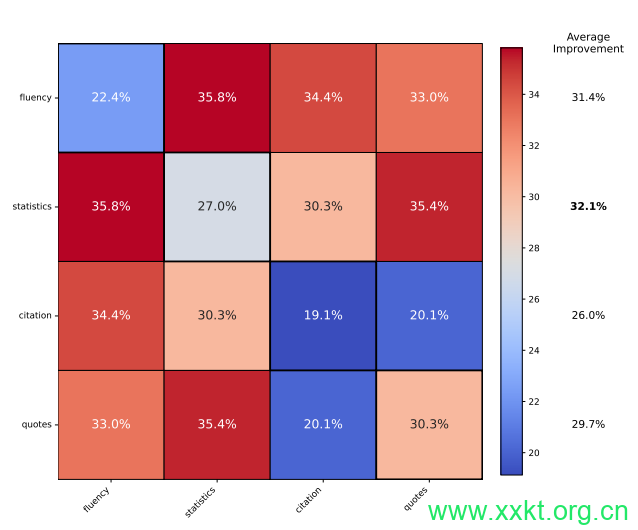
图4:使用GEO策略组合后的相对提升。同时使用流畅度优化和统计量添加可获得最佳性能。
最右侧一列显示,将流畅度优化与其他策略结合使用最为有益。
5.2 多个网站的优化
在生成引擎不断发展的格局中,预计GEO(生成式优化)方法将被广泛采用,从而形成一种所有源内容均使用GEO进行优化的场景。为了理解这一影响,我们通过同时优化所有源内容对GEO方法进行了评估,结果如表2所示。一个关键观察结果是,GEO对网站的影响因其搜索引擎结果页面(SERP)排名而异。
值得注意的是,通常难以获得知名度的低排名网站从GEO中获益更多。这是因为传统搜索引擎依赖于多个因素,如反向链接的数量和域名存在情况,这些对于小型创作者来说难以实现。然而,由于生成式搜索引擎利用基于网站内容的生成模型,反向链接建设等因素不会让小型创作者处于不利地位。
表2所示的可见度相对提升情况证明了这一点。例如,对于在搜索引擎结果页面(SERP)中排名第五的网站,引用来源(Cite Sources)方法使其可见度大幅提高了115.1%,而排名第一的网站的可见度平均下降了30.3%。
这一发现凸显了GEO作为使数字空间民主化的工具的潜力。许多排名较低的网站都是由小型内容创作者或独立企业,传统上在顶级搜索引擎结果中难以与大型企业竞争。生成引擎的出现,初看起来似乎对这些小型实体不利。然而,生成引擎优化(GEO)方法的应用为这些内容创作者提供了一个机会,可以显著提高他们在生成引擎响应中的可见度。通过使用GEO增强其内容,他们可以触及更广泛的受众,从而创造公平的竞争环境,使他们能够更有效地与大型企业竞争。
表4:优化源网站的GEO方法代表性示例。添加内容以绿色标记,删除内容以红色标记。在不增加任何实质性新信息的情况下,GEO方法显著提高了源内容的可见度。

5.3 GEO策略的组合
尽管单个GEO策略在各个领域都取得了显著进步,但在实践中,网站所有者需要结合使用多种策略。为了研究结合使用GEO策略所带来的性能提升,我们考虑了表现最佳的四种GEO方法(即引用来源、流畅度优化、统计数据添加和引用添加)的所有组合。图4展示了结合不同GEO策略后,位置调整词数可见性指标相对提升的热力图。
分析表明,生成引擎优化(Generative Engine Optimization,GEO)方法的组合能够提升性能,其中最佳组合(流畅度优化和统计量增加)的性能优于任何单一GEO策略5.5%以上4。
此外,与其他方法结合使用时,引用来源(Cite Sources)能显著提升性能(平均提升31.4%),尽管单独使用时效果相对较差(比引用添加低8%)。这一发现凸显了研究GEO方法组合的重要性,因为内容创作者在现实世界中可能会使用这些方法。
5.4 定性分析
我们在表4中对生成性引擎(GEO)方法进行了定性分析,其中包含了一些代表性示例,展示了GEO方法如何在最小化改动的情况下提高来源可见性。每种方法都通过适当的文本增减来优化来源。在第一个示例中,我们发现仅需在陈述中添加来源即可显著提高最终答案中的可见性,而内容创作者只需付出最小的努力。第二个示例表明,尽可能添加相关统计数据可确保在生成引擎的最终回复中提高来源可见性。最后,第三行表明,仅通过强调文本部分并使用有说服力的文本风格,也能提高可见性。
6 自然环境中的GEO
自然环境中的GEO:已部署生成引擎的实验
表5:在GEO-bench上使用Perplexity.ai作为GE的GEO方法的绝对印象指标。而SEO方法,诸如关键词堆砌等表现不佳的方法,我们提出的GEO方法能够很好地推广到多个生成引擎,显著提高内容可见度。
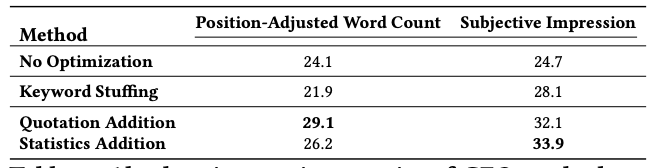
为了验证我们提出的生成引擎优化方法的有效性,我们在Perplexity.ai上对其进行了评估,这是一个真实部署的生成引擎,拥有庞大的用户基础。结果见表5。与我们的生成引擎类似,报价添加在位置调整词数方面表现最佳,比基线提高了22%。
在我们的生成引擎中表现良好的方法,如“引用来源”和“统计数据添加”,在这两项指标上分别提升了高达9%和37%。我们的观察结果进一步凸显,例如关键词堆砌等传统SEO方法效果不佳,其表现比基线差10%。
这些结果意义重大,原因有三:
1)它们强调了开发不同的生成引擎优化(Generative Engine Optimization,GEO)方法对内容创作者的重要性;
2)它们凸显了我们提出的GEO方法在不同生成引擎上的普适性;
3)它们证明内容创作者可以直接使用我们易于实施的GEO方法,从而产生巨大的现实影响。更多详情请参阅附录C.1。
7 相关研究
基于证据的答案生成:先前的研究采用了多种技术来生成基于源的答案。Nakano等人[19]训练了GPT-3,使其能够在网络环境中浏览并生成基于源的答案。
同样,其他方法[17, 23, 24]通过搜索引擎获取资源以生成答案。我们的工作将这些方法统一起来,并为未来改进这些系统提供了一个共同的基准。在最近的一份工作草案中,Kumar和Lakkaraju[11]表明,策略性文本序列可以操纵大型语言模型(LLM)的推荐,以提高生成式引擎中产品的可见度。
他们的方法侧重于通过对抗性文本来提高产品可见度,而我们的方法则引入了非对抗性策略来优化任何网站内容,以提高其在生成式引擎搜索结果中的可见度。检索增强语言模型:最近的一些研究通过从知识库中获取相关资源来完成任务,从而解决了语言模型记忆有限的问题[3, 9, 18]。
然而,生成引擎需要生成答案,并在整个答案中提供归因。此外,生成引擎在输入和输出方面并不局限于单一的文本形式。另外,生成引擎的框架不仅限于获取相关来源,而是包括多个任务,如查询重构、来源选择以及决定如何以及何时执行这些任务。
搜索引擎优化:在过去的近25年里,人们进行了大量研究,旨在优化网页内容以提升搜索引擎排名[2, 12, 22]。这些方法分为站内搜索引擎优化(On-Page SEO)和站外搜索引擎优化(Off-Page SEO)。站内搜索引擎优化旨在改进内容和用户体验,而站外搜索引擎优化则通过链接建设来提升网站权威性。相比之下,GEO所处理的环境更为复杂,涉及多模态和对话式设置。
由于生成式优化(GEO)针对的是一种不限于简单关键词匹配的生成式模型,因此传统的搜索引擎优化(SEO)策略并不适用于生成式引擎的设置,这凸显了生成式优化的必要性。
8 结论
在本研究中,我们构建了融合生成模型的搜索引擎,并将其命名为生成引擎。我们提出了生成引擎优化(GEO)方法,以助力内容创作者在生成引擎下优化其内容。
我们为生成引擎定义了印象指标,并提出并发布了GEO-bench:一个包含来自多个领域和设置的不同用户查询的基准测试,以及回答这些查询所需的相关资源。我们提出了几种优化生成引擎内容的方法,并证明这些方法可以将生成引擎响应中的资源可见度提高多达40%。
除其他发现外,我们还表明,纳入引用、相关来源的引文和统计数据可以显著提高来源的可见度。此外,我们还发现,GEO方法的有效性依赖于查询领域,以及结合多种GEO策略的潜力。
我们在一个拥有数百万活跃用户的商用生成引擎上展示了有前景的结果,展示了我们的工作对现实世界的影响。总之,我们的工作是首个将重要且及时的生成引擎优化(GEO)范式形式化的工作,我们发布了算法和基础设施(基准测试、数据集和指标),以促进社区在生成引擎方面的快速进展。
这是理解生成引擎对数字空间的影响以及生成引擎组织(GEO)在这种新型搜索引擎范式中的作用的第一步。
9 限制
虽然我们在两个生成引擎(包括一个公开可用的引擎)上对我们提出的方法进行了严格测试,但随着生成引擎(GEs)的发展,这些方法可能需要随着时间的推移而进行调整,以反映搜索引擎优化(SEO)的发展。此外,尽管我们努力确保GEObench中的查询与真实世界的查询非常相似,但查询的性质会随时间而变化,因此需要不断更新。
此外,由于搜索引擎算法的黑箱特性,我们并未评估地理优化(GEO)方法对搜索排名的影响。然而,我们注意到,地理优化方法所做的更改是针对文本内容的有针对性的更改,与搜索引擎优化(SEO)方法有些相似,同时不会影响域名、反向链接等其他元数据,因此,它们不太可能影响搜索引擎排名。
此外,随着语言模型中上下文长度增大带来的经济性提升,预计未来的生成模型将能够处理更多来源,从而降低搜索排名的影响。最后,尽管我们提出的GEO-bench中的每个查询都已标记并经过人工检查,但由于主观解读或标注错误,可能仍存在差异。
10 致谢
本材料基于美国国家科学基金会资助的项目,资助编号为2107048。本材料中表达的任何观点、发现、结论或建议均属于作者本人,并不一定反映美国国家科学基金会的立场。
清单1:生成引擎所用的提示。生成引擎(GE)接收查询和5个来源作为输入,并输出基于这些来源的查询响应。
会话生成引擎 在2.1节中,我们讨论了一种单轮生成引擎,该引擎根据用户查询输出单一响应。然而,即将问世的生成引擎的一大优势在于它们能够与用户进行活跃的双向对话。
该对话允许用户对其查询或生成引擎的回应进行澄清,并提出后续问题。具体而言,在等式1中,输入不是单个查询𝑞𝑢,而是被建模为对话历史𝐻 = (𝑞 𝑡 𝑢 , 𝑟𝑡 )对。然后,回应𝑟 𝑡+1被定义为:
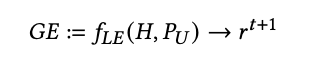
其中𝑡表示轮次。此外,为了与用户进行对话,一个单独的大型语言模型(LLM),𝐿𝑓 𝑜𝑙𝑙𝑜𝑤或𝐿𝑟𝑒𝑠𝑝,可以根据𝐻、𝑃𝑈和𝑟 𝑡+1生成建议的后续问题。
建议的后续问题通常旨在最大限度地提高用户参与度。这不仅有利于生成引擎提供商通过增加用户互动来获益,也有利于网站所有者通过提高其可见度来获益。此外,这些后续问题还可以通过获取更详细的信息来帮助用户。
B 实验设置 B.1 评估生成引擎 所使用的确切提示如清单1所示。B.2 基准测试 GEO-bench包含来自九个数据集的查询。每个数据集的代表性查询如图2所示。此外,我们根据7个不同类别的集合对每个查询进行标记。
在标注方面,我们使用GPT-4模型,并手动确认标注的高召回率和精确率。然而,由于这是一个自动化系统,标注结果可能存在噪声,不应过于仔细地考虑。以下是对每个查询的详细说明:
列表2:GEO-bench中9个数据集各自的代表性查询

• 难度等级:查询的复杂程度,从简单到复杂不等。
• 查询性质:查询所寻求的信息类型,如事实、观点或比较。
• 类型:查询所属的类别或领域,如艺术与娱乐、金融或科学。
• 具体主题:查询的具体主题内容,如物理学、经济学或计算机科学。
• 敏感性:查询内容是否涉及敏感话题。
• 用户意图:用户查询背后的目的,如研究、购买或娱乐。
• 答案类型:查询所寻求的答案的格式,如事实、观点或列表。
B.3 评估指标 我们使用了7种不同的主观印象指标,其提示信息已发布在我们的公共存储库中:
https://github .com/GEOoptim/GEO。 B.4 GEO方法 我们提出了9种不同的生成引擎优化方法,以针对生成引擎优化网站内容。
我们在完整的GEO-bench测试集上评估了这些方法。此外,为了减少结果中的方差,我们在五个不同的随机种子下进行了实验,并报告了平均结果。
B.5 GEO方法的提示 我们在公共存储库中提供了所有提示:https://github .com/GEO-optim/GEO。所有实验均使用GPT-3.5 turbo进行。C 结果 我们在5个随机种子上进行实验,并在表6中展示了带有统计偏差的结果
C.1 生成引擎在现实世界中的应用:已部署生成引擎的实验 我们还评估了我们提出的生成引擎优化方法在现实世界中已部署的生成引擎Perplexity.ai上的表现。由于perplexity.ai不允许用户指定源URL,我们改为将源文本作为文件上传到perplexity.ai,同时确保所有答案仅使用提供的文件源生成。我们在测试集的200个样本子集上评估了我们的所有方法。使用Perplexity.ai得到的结果如表7所示。
REFERENCES(参考文献)
[1] Daria Alexander, Wojciech Kusa, and Arjen P. de Vries. 2022. ORCAS-I: Queries Annotated with Intent using Weak Supervision. Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (2022). https://api.semanticscholar.org/CorpusID:248495926 [2] Prashant Ankalkoti. 2017. Survey on Search Engine Optimization Tools & Techniques. Imperial journal of interdisciplinary research 3 (2017). https: //api.semanticscholar.org/CorpusID:116487363 [3] Akari Asai, Xinyan Velocity Yu, Jungo Kasai, and Hannaneh Hajishirzi. 2021. One Question Answering Model for Many Languages with Cross-lingual Dense Passage Retrieval. In Neural Information Processing Systems. https: //api.semanticscholar.org/CorpusID:236428949 [4] Sergey Brin and Lawrence Page. 1998. The Anatomy of a Large-Scale Hypertextual Web Search Engine. Comput. Networks 30 (1998), 107–117. https: //api.semanticscholar.org/CorpusID:7587743 [5] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (Eds.), Vol. 33. Curran Associates, Inc., 1877–1901. https://proceedings.neurips.cc/paper_files/paper/2020/file/ 1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf [6] Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Fernando Campos, and Jimmy J. Lin. 2021. MS MARCO: Benchmarking Ranking Models in the Large-Data Regime. Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (2021). https://api.semanticscholar.org/ CorpusID:234336491 [7] Brian Dean. 2023. We Analyzed 4 Million Google Search Results. Here’s What We Learned About Organic Click Through Rate. https://backlinko.com/googlectr-stats Accessed: 2024-06-08. [8] Danny Goodwin. 2011. Top Google Result Gets 36.4% of Clicks [Study]. https://www.searchenginewatch.com/2011/04/21/top-google-resultgets-36-4-of-clicks-study/ [9] Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. 2020. REALM: Retrieval-Augmented Language Model Pre-Training. ArXiv abs/2002.08909 (2020). https://api.semanticscholar.org/CorpusID:211204736 [10] Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. Comput. Surveys 55, 12 (2023), 1–38. [11] Aounon Kumar and Himabindu Lakkaraju. 2024. Manipulating Large Language Models to Increase Product Visibility. arXiv:2404.07981 [cs.IR] [12] R.Anil Kumar, Zaiduddin Shaik, and Mohammed Furqan. 2019. A Survey on Search Engine Optimization Techniques. International Journal of P2P Network Trends and Technology (2019). https://doi.org/10.14445/22492615/IJPTT-V9I1P402 [13] Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur P. Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc V. Le, and Slav Petrov. 2019. Natural Questions: A Benchmark for Question Answering Research. Transactions of the Association for Computational Linguistics 7 (2019), 453–466. https: //api.semanticscholar.org/CorpusID:86611921 [14] Nelson F. Liu, Tianyi Zhang, and Percy Liang. 2023. Evaluating Verifiability in Generative Search Engines. ArXiv abs/2304.09848 (2023). https://api. semanticscholar.org/CorpusID:258212854 [15] Yang Liu, Dan Iter, Yichong Xu, Shuo Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. ArXiv abs/2303.16634 (2023). https://api.semanticscholar.org/CorpusID:257804696 [16] G. D. Maayan. 2023. How Google SGE will impact your traffic – and 3 SGE recovery case studies. Search Engine Land (5 Sep 2023). https://searchengineland.com/how-google-sge-will-impact-your-trafficand-3-sge-recovery-case-studies-431430 [17] Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, and Nathan McAleese. 2022. Teaching language models to support answers with verified quotes. ArXiv abs/2203.11147 (2022). https: //api.semanticscholar.org/CorpusID:247594830 [18] Grégoire Mialon, Roberto Dessì, Maria Lomeli, Christoforos Nalmpantis, Ramakanth Pasunuru, Roberta Raileanu, Baptiste Rozière, Timo Schick, Jane Dwivedi-Yu, Asli Celikyilmaz, Edouard Grave, Yann LeCun, and Thomas Scialom. 2023. Augmented Language Models: a Survey. ArXiv abs/2302.07842 (2023). https://api.semanticscholar.org/CorpusID:256868474 [19] Reiichiro Nakano, Jacob Hilton, S. Arun Balaji, Jeff Wu, Ouyang Long, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. 2021. WebGPT: Browser-assisted question-answering with human feedback. ArXiv abs/2112.09332 (2021). https: //api.semanticscholar.org/CorpusID:245329531 [20] OpenAI. 2022. Introducing ChatGPT. https://openai.com/index/chatgpt/ [21] OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner, Lenny Bogdonoff, Oleg Boiko, Madelaine Boyd, Anna-Luisa Brakman, Greg Brockman, Tim Brooks,Miles Brundage, Kevin Button, Trevor Cai, Rosie Campbell, Andrew Cann, Brittany Carey, Chelsea Carlson, Rory Carmichael, Brooke Chan, Che Chang, Fotis Chantzis, Derek Chen, Sully Chen, Ruby Chen, Jason Chen, Mark Chen, Ben Chess, Chester Cho, Casey Chu, Hyung Won Chung, Dave Cummings, Jeremiah Currier, Yunxing Dai, Cory Decareaux, Thomas Degry, Noah Deutsch, Damien Deville, Arka Dhar, David Dohan, Steve Dowling, Sheila Dunning, Adrien Ecoffet, Atty Eleti, Tyna Eloundou, David Farhi, Liam Fedus, Niko Felix, Simón Posada Fishman, Juston Forte, Isabella Fulford, Leo Gao, Elie Georges, Christian Gibson, Vik Goel, Tarun Gogineni, Gabriel Goh, Rapha Gontijo-Lopes, Jonathan Gordon, Morgan Grafstein, Scott Gray, Ryan Greene, Joshua Gross, Shixiang Shane Gu, Yufei Guo, Chris Hallacy, Jesse Han, Jeff Harris, Yuchen He, Mike Heaton, Johannes Heidecke, Chris Hesse, Alan Hickey, Wade Hickey, Peter Hoeschele, Brandon Houghton, Kenny Hsu, Shengli Hu, Xin Hu, Joost Huizinga, Shantanu Jain, Shawn Jain, Joanne Jang, Angela Jiang, Roger Jiang, Haozhun Jin, Denny Jin, Shino Jomoto, Billie Jonn, Heewoo Jun, Tomer Kaftan, Łukasz Kaiser, Ali Kamali, Ingmar Kanitscheider, Nitish Shirish Keskar, Tabarak Khan, Logan Kilpatrick, Jong Wook Kim, Christina Kim, Yongjik Kim, Jan Hendrik Kirchner, Jamie Kiros, Matt Knight, Daniel Kokotajlo, Łukasz Kondraciuk, Andrew Kondrich, Aris Konstantinidis, Kyle Kosic, Gretchen Krueger, Vishal Kuo, Michael Lampe, Ikai Lan, Teddy Lee, Jan Leike, Jade Leung, Daniel Levy, Chak Ming Li, Rachel Lim, Molly Lin, Stephanie Lin, Mateusz Litwin, Theresa Lopez, Ryan Lowe, Patricia Lue, Anna Makanju, Kim Malfacini, Sam Manning, Todor Markov, Yaniv Markovski, Bianca Martin, Katie Mayer, Andrew Mayne, Bob McGrew, Scott Mayer McKinney, Christine McLeavey, Paul McMillan, Jake McNeil, David Medina, Aalok Mehta, Jacob Menick, Luke Metz, Andrey Mishchenko, Pamela Mishkin, Vinnie Monaco, Evan Morikawa, Daniel Mossing, Tong Mu, Mira Murati, Oleg Murk, David Mély, Ashvin Nair, Reiichiro Nakano, Rajeev Nayak, Arvind Neelakantan, Richard Ngo, Hyeonwoo Noh, Long Ouyang, Cullen O’Keefe, Jakub Pachocki, Alex Paino, Joe Palermo, Ashley Pantuliano, Giambattista Parascandolo, Joel Parish, Emy Parparita, Alex Passos, Mikhail Pavlov, Andrew Peng, Adam Perelman, Filipe de Avila Belbute Peres, Michael Petrov, Henrique Ponde de Oliveira Pinto, Michael, Pokorny, Michelle Pokrass, Vitchyr H. Pong, Tolly Powell, Alethea Power, Boris Power, Elizabeth Proehl, Raul Puri, Alec Radford, Jack Rae, Aditya Ramesh, Cameron Raymond, Francis Real, Kendra Rimbach, Carl Ross, Bob Rotsted, Henri Roussez, Nick Ryder, Mario Saltarelli, Ted Sanders, Shibani Santurkar, Girish Sastry, Heather Schmidt, David Schnurr, John Schulman, Daniel Selsam, Kyla Sheppard, Toki Sherbakov, Jessica Shieh, Sarah Shoker, Pranav Shyam, Szymon Sidor, Eric Sigler, Maddie Simens, Jordan Sitkin, Katarina Slama, Ian Sohl, Benjamin Sokolowsky, Yang Song, Natalie Staudacher, Felipe Petroski Such, Natalie Summers, Ilya Sutskever, Jie Tang, Nikolas Tezak, Madeleine B. Thompson, Phil Tillet, Amin Tootoonchian, Elizabeth Tseng, Preston Tuggle, Nick Turley, Jerry Tworek, Juan Felipe Cerón Uribe, Andrea Vallone, Arun Vijayvergiya, Chelsea Voss, Carroll Wainwright, Justin Jay Wang, Alvin Wang, Ben Wang, Jonathan Ward, Jason Wei, CJ Weinmann, Akila Welihinda, Peter Welinder, Jiayi Weng, Lilian Weng, Matt Wiethoff, Dave Willner, Clemens Winter, Samuel Wolrich, Hannah Wong, Lauren Workman, Sherwin Wu, Jeff Wu, Michael Wu, Kai Xiao, Tao Xu, Sarah Yoo, Kevin Yu, Qiming Yuan, Wojciech Zaremba, Rowan Zellers, Chong Zhang, Marvin Zhang, Shengjia Zhao, Tianhao Zheng, Juntang Zhuang, William Zhuk, and Barret Zoph. 2024. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL] [22] A. Shahzad, Deden Witarsyah Jacob, Nazri M. Nawi, Hairulnizam Bin Mahdin, and Marheni Eka Saputri. 2020. The new trend for search engine optimization, tools and techniques. Indonesian Journal of Electrical Engineering and Computer Science 18 (2020), 1568. https://api.semanticscholar.org/CorpusID:213123106 [23] Kurt Shuster, Jing Xu, Mojtaba Komeili, Da Ju, Eric Michael Smith, Stephen Roller, Megan Ung, Moya Chen, Kushal Arora, Joshua Lane, Morteza Behrooz, W.K.F. Ngan, Spencer Poff, Naman Goyal, Arthur Szlam, Y-Lan Boureau, Melanie Kambadur, and Jason Weston. 2022. BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage. ArXiv abs/2208.03188 (2022). https://api.semanticscholar.org/CorpusID:251371589 [24] Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, YaGuang Li, Hongrae Lee, Huaixiu Steven Zheng, Amin Ghafouri, Marcelo Menegali, Yanping Huang, Maxim Krikun, Dmitry Lepikhin, James Qin, Dehao Chen, Yuanzhong Xu, Zhifeng Chen, Adam Roberts, Maarten Bosma, Vincent Zhao, Yanqi Zhou, Chung-Ching Chang, Igor Krivokon, Will Rusch, Marc Pickett, Pranesh Srinivasan, Laichee Man, Kathleen Meier-Hellstern, Meredith Ringel Morris, Tulsee Doshi, Renelito Delos Santos, Toju Duke, Johnny Soraker, Ben Zevenbergen, Vinodkumar Prabhakaran, Mark Diaz, Ben Hutchinson, Kristen Olson, Alejandra Molina, Erin Hoffman-John, Josh Lee, Lora Aroyo, Ravi Rajakumar, Alena Butryna, Matthew Lamm, Viktoriya Kuzmina, Joe Fenton, Aaron Cohen, Rachel Bernstein, Ray Kurzweil, Blaise Aguera-Arcas, Claire Cui, Marian Croak, Ed Chi, and Quoc Le. 2022. LaMDA: Language Models for Dialog Applications. arXiv:2201.08239 [cs.CL] [25] Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, L. Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. 2023. LIMA: Less Is More for Alignment. ArXiv abs/2305.11206 (2023). https://api.semanticscholar.org/CorpusID:258822910
以上就是GEO小小课堂网( https://www.xxkt.org.cn/ )带来的是《普林斯顿大学2024年GEO论文中文翻译版》。感谢您的观看。
非特殊说明,本文为小小课堂SEO自学网原创,欢迎转载并保留版权 https://www.xxkt.org.cn/
本站提供SEO与GEO培训、咨询、诊断,微信(电话):13722793092 微信公众号:xxktorg
标签:Generative Engine Optimization, GEO论文, 普林斯顿大学GEO论文 文章最后更新时间:六月 8, 2026

发表评论