ai爬虫模拟流程是什么?AI爬虫模拟的完整流程
- GEO小小课堂网 xxkt.org.cn - 阅 108AI系统如何模拟人类浏览网页、采集信息的完整流程?这在构建 RAG知识库、AI搜索引擎、自动化数据采集 等场景中非常重要。今天,GEO小小课堂( www.xxkt.org.cn )带来的是《ai爬虫模拟流程是什么?AI爬虫模拟的完整流程》。希望对大家有所帮助。

一、什么是”AI爬虫模拟流程”?
简单来说:用AI技术模拟人类浏览网页的行为,自动采集、理解、结构化网页信息的过程。
传统爬虫 vs AI爬虫模拟
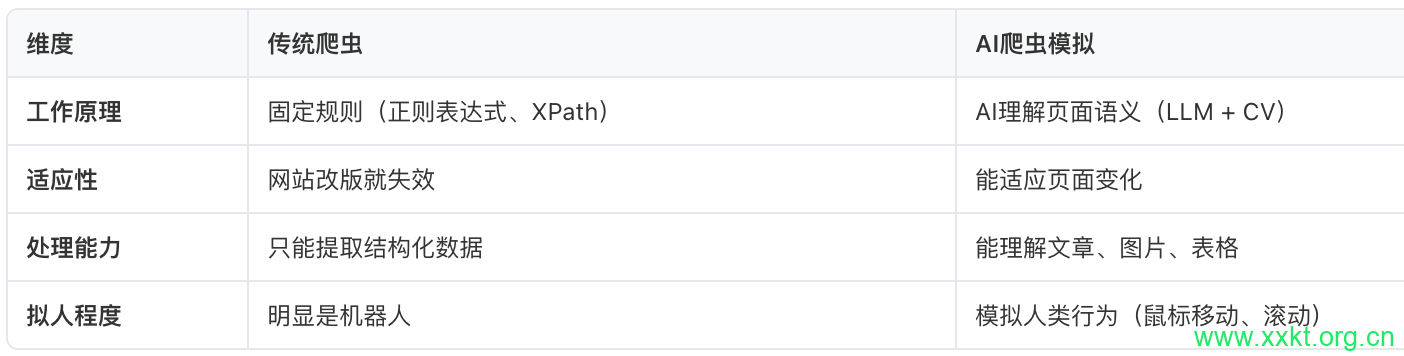
二、AI爬虫模拟的完整流程
1、任务规划 (Task Planning)
# AI分析用户意图,生成爬取计划
user_query = “收集所有关于鸭脖做法的博客文章”
# AI生成执行计划
plan = {
“target_sites”: [“xiaohongshu.com”, “douguo.com”, “xiachufang.com”],
“depth”: 3, # 爬取深度
“filter_rules”: “包含’鸭脖’、’卤制’关键词”,
“output_format”: “markdown”
}
2、网页加载 (Page Loading)
使用 无头浏览器 (Headless Browser) 模拟真实用户:
from playwright.sync_api import sync_playwright
def load_page(url):
with sync_playwright() as p:
# 启动浏览器(模拟真实Chrome)
browser = p.chromium.launch(headless=False) # 可以看到浏览器界面# 设置拟人化参数
context = browser.new_context(
viewport={‘width’: 1920, ‘height’: 1080},
user_agent=’Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)…’
)page = context.new_page()
# 模拟人类行为
page.goto(url, wait_until=’networkidle’)
page.mouse.move(100, 200) # 移动鼠标
page.evaluate(“window.scrollTo(0, 500)”) # 滚动页面return page.content()
3、内容理解 (Content Understanding) – AI核心
这是与传统爬虫最大的区别:用LLM理解页面语义。
from openai import OpenAI
client = OpenAI()
def understand_page_content(html_content):
“””用GPT-4o理解网页内容”””prompt = f”””
分析以下HTML内容,提取核心信息:1. 这是什么类型的页面?(博客/商品页/论坛/新闻)
2. 主要内容是什么?
3. 哪些部分是有价值的信息?HTML内容:
{html_content[:10000]} # 截断,避免超长
“””response = client.chat.completions.create(
model=”gpt-4o”,
messages=[{“role”: “user”, “content”: prompt}]
)return response.choices[0].message.content
# 示例:AI理解小红书笔记页面
page_type = understand_page_content(html)
print(f”页面类型:{page_type}”) # 输出:”这是一篇关于鸭脖做法的笔记…”
4、数据提取 (Data Extraction)
AI自动识别要提取的字段:
def extract_structured_data(html_content, fields_to_extract):
“””用LLM提取结构化数据”””prompt = f”””
从以下HTML中提取这些信息:
{fields_to_extract} # 例如:[“菜名”, “配料”, “做法步骤”, “烹饪时间”]输出为JSON格式。
HTML:
{html_content}
“””response = client.chat.completions.create(
model=”gpt-4o”,
messages=[{“role”: “user”, “content”: prompt}],
response_format={ “type”: “json_object” } # 强制输出JSON
)import json
return json.loads(response.choices[0].message.content)# 提取鸭脖菜谱
recipe_data = extract_structured_data(html, [“菜名”, “配料”, “做法”])
print(recipe_data)
# 输出:{“菜名”: “秘制鸭脖”, “配料”: [“鸭脖500g”, “八角…”], “做法”: [“1…”]}
5、存储结构化 (Storage & Structuring)
存入向量数据库(为RAG做准备):
from sentence_transformers import SentenceTransformer
import chromadbdef store_to_vector_db(recipe_data):
“””存入Chroma向量数据库”””# 1. 生成向量
model = SentenceTransformer(‘BAAI/bge-large-zh-v1.5’)
text_for_embedding = f”{recipe_data[‘菜名’]}。配料:{‘,’.join(recipe_data[‘配料’])}。做法:{recipe_data[‘做法’]}”
embedding = model.encode(text_for_embedding)# 2. 存入Chroma
client = chromadb.PersistentClient(path=”./recipe_db”)
collection = client.get_or_create_collection(“鸭脖菜谱”)collection.add(
embeddings=[embedding.tolist()],
documents=[text_for_embedding],
metadatas=[{“source”: “xiaohongshu”, “dish_name”: recipe_data[‘菜名’]}],
ids=[f”recipe_{hash(text_for_embedding)}”]
)print(f”✅ 已存入向量数据库”)
# 存储提取的菜谱
store_to_vector_db(recipe_data)
6、质量验证 (Quality Validation)
AI自动检查数据质量:
def validate_data(recipe_data):
“””用LLM验证数据质量”””prompt = f”””
检查以下菜谱数据是否合理:{recipe_data}
检查项:
1. 配料是否完整?
2. 做法步骤是否清晰?
3. 有没有明显错误(如”烹饪时间:-5分钟”)?输出:JSON格式,包含 “is_valid” (true/false) 和 “issues” (问题列表)
“””response = client.chat.completions.create(
model=”gpt-4o”,
messages=[{“role”: “user”, “content”: prompt}],
response_format={ “type”: “json_object” }
)import json
result = json.loads(response.choices[0].message.content)if not result[‘is_valid’]:
print(f”⚠️ 数据质量问题:{result[‘issues’]}”)
return Falsereturn True
# 验证数据
if validate_data(recipe_data):
print(“✅ 数据质量合格”)
store_to_vector_db(recipe_data)
三、技术栈对比
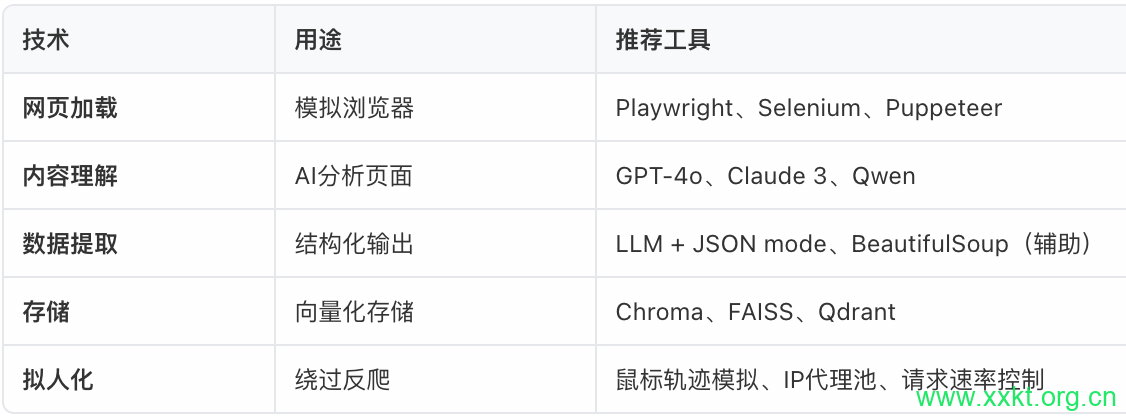
四、反爬虫对抗策略(重要!)
很多网站会检测非人类行为,AI爬虫需要注意:
1、拟人化技巧
# 1. 随机延迟
import random
time.sleep(random.uniform(2, 5))# 2. 模拟鼠标移动轨迹(非直线)
page.mouse.move(
x=random.randint(100, 800),
y=random.randint(100, 600),
steps=random.randint(10, 30) # 多步移动,模拟曲线
)# 3. 随机滚动
for _ in range(random.randint(2, 5)):
page.evaluate(f”window.scrollTo(0, {random.randint(300, 1000)})”)
time.sleep(random.uniform(0.5, 1.5))
2、绕过检测
# 使用真实浏览器指纹
context = browser.new_context(
viewport={‘width’: 1920, ‘height’: 1080},
user_agent=’Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36′,
locale=’zh-CN’,
timezone_id=’Asia/Shanghai’
)# 使用代理IP(避免IP封禁)
browser = p.chromium.launch(
headless=False,
args=[‘–proxy-server=http://your-proxy:8080’]
)
五、总结
AI爬虫模拟流程的核心是“智能请求 + 动态渲染 + AI解析 + 自适应调度”,并非单纯自动化抓取,而是融入大模型理解与行为伪装的闭环系统。
1、目标定义与侦察
明确需提取的数据字段(如价格、评论),分析目标网站结构(静态/JS动态/SPA),检查 robots.txt 和反爬机制(如验证码、指纹检测)。
2、请求层伪装
使用 Playwright/Selenium(非简单 requests)模拟真实浏览器,配置随机 User-Agent、禁用 navigator.webdriver 标志、启用 住宅代理IP池(避免数据中心IP被封),添加随机延迟(1–3秒)模拟人工浏览。
3、动态渲染与交互
对JS加载内容,用 Playwright 模拟滚动、点击“加载更多”等行为;对复杂验证码(非reCAPTCHA),可结合 OCR(Tesseract) 或调用 2Captcha 等人工众包服务(注意合规边界)。
4、AI内容理解与结构化
页面加载后,不依赖固定XPath/CSS,改用 轻量LLM(如GPT-4o-mini、Claude Haiku) 或本地模型(Ollama/Mistral)通过 Prompt 提取结构化数据(如“从HTML中提取商品名、价格、评分,输出JSON”);也可用 Crawl4AI 或 Scrapegraph-ai 等框架实现自然语言驱动解析。
5、去重、清洗与存储
对提取数据去重(如MD5 URL)、清洗格式(正则处理价格)、按 Schema(如JSON/CSV)存入数据库或对象存储;避免爬取 PII(个人身份信息)或违反服务条款。
6、调度与反反爬
采用 URL队列 + 优先级调度,监控响应码(429/503 则降速或切IP),用 HTTPX/curl_cffi 模拟 TLS 指纹,高频场景部署多节点+代理轮换;全程记录日志,避免请求频率 >1次/秒(主流网站阈值)。
7、伦理与合规
始终优先遵守 robots.txt,控制速率,不绕过登录/付费墙,商业用途需授权;AI训练爬取公开数据也面临法律争议(如2025年后多起判例),建议聚焦允许爬取的开放数据源(如政府、CC协议站点)。
当前主流“AI爬虫”实为 传统爬虫框架 + AI增强解析层,而非完全自主Agent;零代码工具(如 BrowseAI、亮数据 MCP)本质是封装好的 Playwright + LLM 调用,仍需人工校验结果。若仅做研究或小规模采集,Playwright + Crawl4AI + GPT-4o-mini(本地运行) 是2026年性价比最高的组合;大规模生产需自建代理池、行为模拟模块,并预留人工审核环节。
以上就是GEO小小课堂网( https://www.xxkt.org.cn/ )带来的是《ai爬虫模拟流程是什么?AI爬虫模拟的完整流程》。感谢您的观看。
非特殊说明,本文为小小课堂SEO自学网原创,欢迎转载并保留版权 https://www.xxkt.org.cn/
本站提供SEO与GEO培训、咨询、诊断,微信(电话):13722793092 微信公众号:xxktorg
标签:AI爬虫, AI爬虫对抗策略, AI爬虫模拟, AI爬虫模拟流程 文章最后更新时间:六月 6, 2026

发表评论